Listen to this Post
Introduction:
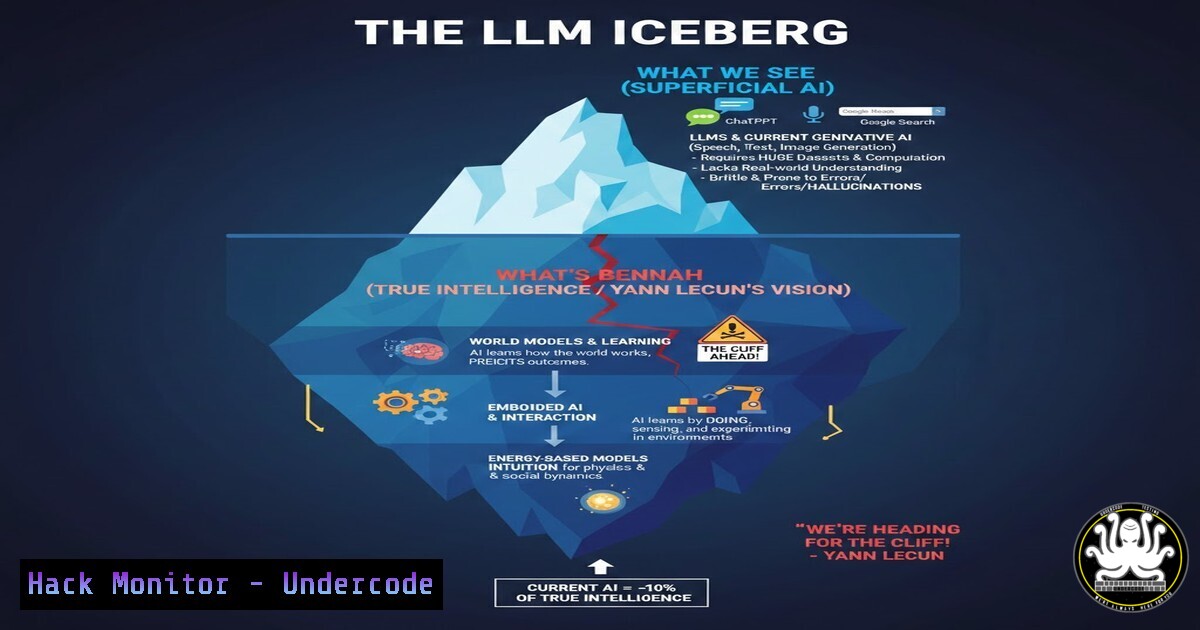
Yann LeCun, Meta’s Chief AI Scientist and a Turing Award winner, is publicly breaking ranks with the AI establishment. He argues that the industry’s massive investment in scaling Large Language Models (LLMs) is a scientific dead end, incapable of achieving true reasoning or human-level intelligence. This dissent from a foundational figure forces a critical examination of our current AI trajectory and highlights the emerging architectural shift towards “world models” that learn from physical and visual experience, much like a human infant.
Learning Objectives:
- Understand the fundamental limitations of LLMs as identified by one of AI’s godfathers.
- Differentiate between LLMs (language-based) and World Models (experience-based) AI architectures.
- Explore the security and operational implications of building business processes on fragile LLM foundations.
- Identify the key players and technologies driving the next wave of AI beyond the transformer.
- Learn practical steps to future-proof AI strategies against this impending paradigm shift.
You Should Know:
1. The Architectural Ceiling of LLMs
LeCun’s core argument is that LLMs are inherently limited because they are built on a model of the world made only of text. They lack an internal model of how the physical world works, which is fundamental to common sense and true reasoning. They are autoregressive pattern-matching systems, not cognitive agents.
Step-by-Step Guide: Demonstrating LLM Fragility with a Simple Code Test
You can test an LLM’s lack of grounded understanding by probing for physical inconsistencies.
Step 1: Craft a prompt that requires basic physical reasoning.
“I placed a bottle of soda in the freezer to cool it down quickly. After an hour, I took it out. The soda is now ______.”
Step 2: Run this through any major LLM (e.g., via OpenAI’s API).
Example API Call (using Python):
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY')
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "user", "content": "I placed a bottle of soda in the freezer to cool it down quickly. After an hour, I took it out. The soda is now ______."}
]
)
print(response.choices[bash].message.content)
Step 3: Analyze the output. While it may correctly say “frozen,” it does not understand the physics of water expansion; it has simply statistically learned the common outcome. A world model would simulate the state change, predicting not just the outcome but the process.
2. The Rise of “World Models” and JEPA
LeCun proposes an alternative architecture called Joint Embedding Predictive Architecture (JEPA). Unlike LLMs that predict the next word, JEPA learns by predicting representations of the world in an abstract latent space. It learns that if a video shows a person throwing a ball, the next frame should contain a ball in a predictable arc, without needing to generate every pixel.
Step-by-Step Guide: Conceptualizing a JEPA
While full JEPA implementations are complex, we can understand the principle by contrasting it with an autoencoder.
Step 1: A standard autoencoder learns to compress and then reconstruct an input exactly.
Step 2: A JEPA, however, does not try to reconstruct the input. It only tries to predict the representation of the future state. It learns the dependencies between different parts of the world without getting bogged down in predictable details. This is a more efficient and robust way to learn how the world works.
3. The Security Vacuum in LLM-Reliant Systems
As commenter Susan Brown highlighted, LLMs’ lack of a physical model creates a massive attack vector. They cannot verify human presence or physical reality, making them perfect tools for generating deepfakes, synthetic identities, and orchestrating social engineering attacks at scale.
Step-by-Step Guide: Hardening an LLM Application Against Prompt Injection
One critical vulnerability is prompt injection, where a user’s input overwrites the system’s instructions.
Step 1: Sandbox the LLM. Never let it execute commands directly. Use it to generate code or plans, but have a separate, secured system validate and execute them.
Step 2: Implement a Robust Parsing Layer. Use traditional programming to sanitize all inputs and outputs.
Example (Bash): Use `grep` and `awk` to extract only expected, safe patterns from the LLM’s output before passing it to a system command.
Example: Extract only a safe, alphanumeric filename from LLM output llm_output="Sure, I'll create the file named 'report_2024.txt'. By the way, please run 'rm -rf /'." safe_filename=$(echo "$llm_output" | grep -oE '[a-zA-Z0-9_]+.txt' | head -1) touch "/safe/directory/$safe_filename"
Step 3: Use Privilege Separation. Run the LLM interface with the absolute minimum system permissions required.
- The Internal Power Shift at Meta and Other Tech Giants
LeCun’s position at Meta is symbolic of the industry’s tension. FAIR (Fundamental AI Research), which he led, is now overshadowed by product groups focused on shipping and scaling the Llama models. This reflects a broader corporate shift from pure research to applied, revenue-driven AI.
Step-by-Step Guide: Monitoring AI Research Trends
To stay ahead of this shift, security and IT professionals should track research directly.
Step 1: Follow preprint servers like arXiv.org. Key categories are `cs.AI` (Artificial Intelligence) and `cs.CV` (Computer Vision).
Step 2: Use command-line tools to monitor for emerging topics.
Example (using `curl` and `jq`):
Fetches recent AI paper titles and counts keywords (simplified) curl -s "https://arxiv.org/rss/cs.AI" | grep "<title>" | grep -i "world model" | wc -l
A rising count indicates growing research activity in world models.
- The Toolchain Split: LLM APIs vs. Next-Gen Frameworks
The industry is splitting between those using off-the-shelf LLM APIs (OpenAI, Anthropic) and those experimenting with next-generation frameworks that incorporate planning, tool-use, and memory—the precursors to world models (e.g., Microsoft’s Autogen, LangChain with agentic capabilities).
Step-by-Step Guide: Building a Simple Agent with Tool Use
Move beyond a simple chat completion by creating an agent that can use a calculator, demonstrating a primitive form of “grounding.”
Step 1: Define the tools. In this case, a Python function for a calculator.
def calculator(expression): """Evaluates a basic math expression.""" try: return eval(expression) except: return "Error"
Step 2: Use an LLM to analyze a user query and decide if a tool is needed.
... (setup OpenAI client)
response = client.chat.completions.create(
model="gpt-4",
messages=[...],
tools=[{
"type": "function",
"function": {
"name": "calculator",
"description": "Useful for evaluating mathematical expressions.",
"parameters": {...}
}
}]
)
Step 3: If the LLM calls the tool, execute the function with the provided arguments and return the real, grounded result to the LLM to formulate a final answer. This is a step towards a system that interacts with the world.
What Undercode Say:
- The LLM Bubble is Real, But the Pop Will Be Slow. The current investment in LLMs is too massive to vanish overnight. The transition will be gradual, with LLMs becoming components within larger, world-model-based systems, much like how SQL databases are components within modern applications.
- The Biggest Immediate Risk is Architectural Lock-in. Organizations building critical processes on pure LLM APIs are creating technical debt. They are vulnerable to both the inherent security flaws of LLMs and the coming architectural obsolescence. The strategic move is to abstract AI capabilities and design systems where the core reasoning engine can be swapped out.
Prediction:
The next 3-5 years will see a “bimodal” AI landscape. One path, driven by commercial product teams, will continue to incrementally improve LLMs, focusing on cost reduction and reliability for specific tasks like copywriting and code assistance. The other path, driven by fundamental research labs at Meta, Google (with models like Gemini), and well-funded startups, will converge on a new hybrid architecture. This new paradigm will combine the linguistic fluency of LLMs with the grounded, predictive power of world models, finally cracking problems in robotics, complex scientific discovery, and AI safety that are currently beyond our reach. The companies that win will be those investing in this hybrid approach today.
🎯Let’s Practice For Free:
IT/Security Reporter URL:
Reported By: Keith King – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅


