Listen to this Post
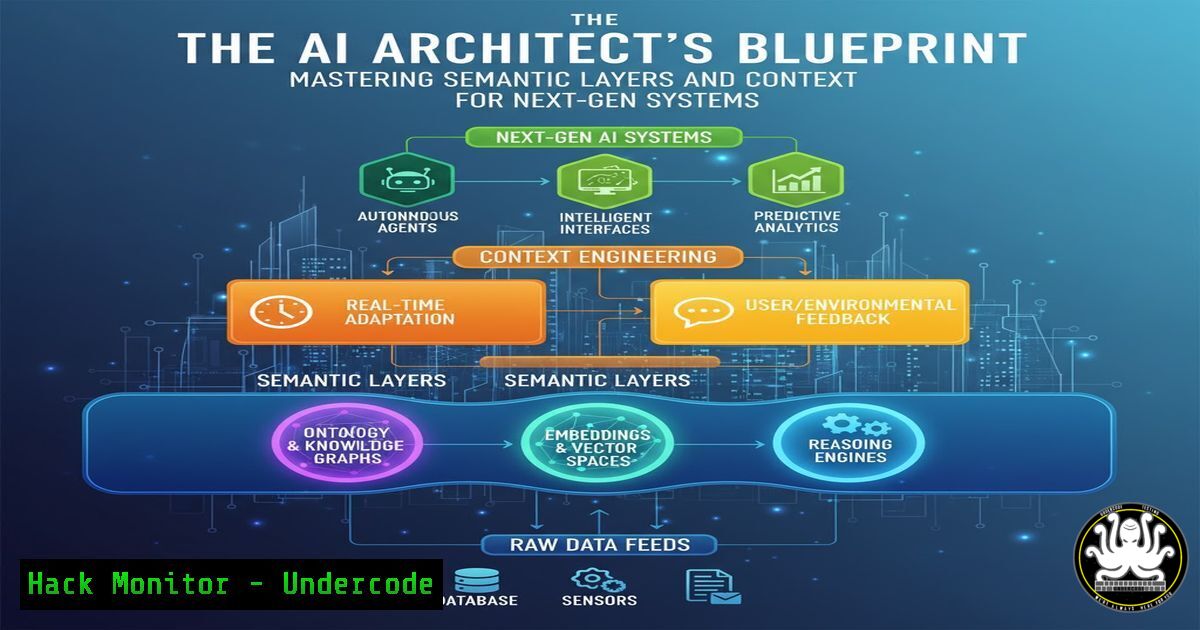
Introduction:
The paradigm of AI development is shifting from simplistic Retrieval-Augmented Generation (RAG) pipelines to sophisticated architectures built on semantic layers and context engineering. This evolution, powered by knowledge graphs, moves AI from a passive query responder to an active, reasoning “expert system” capable of orchestrating complex, agentic workflows. Understanding this architectural shift is no longer optional for professionals building cutting-edge AI applications.
Learning Objectives:
- Deconstruct the core components of a semantic layer and its role in Agentic AI.
- Master practical implementations for building and querying knowledge graphs.
- Learn to engineer and optimize context for superior AI reasoning and automation.
You Should Know:
- Building a Basic Knowledge Graph with Python and RDFLib
Verified Python code snippet for creating a simple knowledge graph:from rdflib import Graph, Namespace, Literal from rdflib.namespace import RDF, RDFS Create a new Graph g = Graph() ex = Namespace("http://example.org/") Define entities and relationships g.add((ex.AgenticAI, RDF.type, ex.Concept)) g.add((ex.KnowledgeGraph, RDF.type, ex.Technology)) g.add((ex.AgenticAI, ex.enhancedBy, ex.KnowledgeGraph)) g.add((ex.ContextEngineering, RDF.type, ex.Methodology)) g.add((ex.KnowledgeGraph, ex.enables, ex.ContextEngineering)) Serialize and save the graph g.serialize('ai_knowledge_graph.ttl', format='turtle') Query the graph query = """ SELECT ?subject ?object WHERE { ?subject ?predicate ?object . } """ for row in g.query(query): print(f"{row.subject} -> {row.object}")Step-by-step guide: This code initializes a knowledge graph using the RDFLib library, defining entities like “AgenticAI” and “KnowledgeGraph” and the relationships between them. The graph is serialized in Turtle format, a standard for semantic web data. The SPARQL query at the end demonstrates how to extract all subject-object pairs from the graph, forming the basis for semantic reasoning.
-
Implementing a Vector Search Index for Hybrid Retrieval
Verified command for creating a ChromaDB vector index:
pip install chromadb
Verified Python code for hybrid semantic search:
import chromadb
from sentence_transformers import SentenceTransformer
Initialize client and model
client = chromadb.Client()
collection = client.create_collection(name="ai_concepts")
model = SentenceTransformer('all-MiniLM-L6-v2')
Add documents with metadata
documents = [
"Agentic AI involves autonomous agents that can pursue complex goals.",
"Knowledge graphs provide a semantic layer for structured data representation.",
"Context engineering is the practice of optimizing information for AI comprehension."
]
metadatas = [{"source": "textbook", "id": 1}, {"source": "research_paper", "id": 2}, {"source": "blog", "id": 3}]
embeddings = model.encode(documents).tolist()
Add to collection
collection.add(
embeddings=embeddings,
documents=documents,
metadatas=metadatas,
ids=["id1", "id2", "id3"]
)
Perform a hybrid query
results = collection.query(
query_embeddings=[model.encode("What is Agentic AI?").tolist()],
n_results=2
)
print(results['documents'])
Step-by-step guide: This setup creates a vector database using ChromaDB. Text documents are converted into numerical embeddings using a sentence transformer model. The `add` method populates the index with both the text and its vector representation. The `query` method performs a semantic search, finding the most conceptually similar documents to the query “What is Agentic AI?”, demonstrating a core retrieval mechanism for a semantic layer.
3. Hardening Your Graph Database: Neo4j Security Configuration
Verified Neo4j configuration commands (neo4j.conf):
Enable encryption for bolt connections dbms.connector.bolt.tls_level=REQUIRED dbms.connector.bolt.listen_address=:7687 Configure strict authentication dbms.security.auth_enabled=true dbms.security.auth_minimum_password_length=12 dbms.security.procedures.unrestricted=apoc.coll. Limit query performance to prevent DoS dbms.transaction.timeout=30s dbms.security.procedures.allowlist=apoc.trigger.,apoc.meta.
Step-by-step guide: These configuration lines, placed in the `neo4j.conf` file, secure a Neo4j graph database instance. They enforce encrypted connections (TLS), mandate strong password policies, and restrict procedure execution to an allowlist to prevent unauthorized code execution. The transaction timeout is a critical setting for mitigating Denial-of-Service (DoS) attacks via expensive queries.
- Automating Contextual Data Ingestion with Python and APIs
Verified Python script for automated knowledge graph population:
import requests
import json
from rdflib import Graph, URIRef
def ingest_api_data_to_graph(api_endpoint, graph):
"""Fetches data from an API and adds it to an RDF graph."""
try:
response = requests.get(api_endpoint, timeout=10)
response.raise_for_status()
data = response.json()
Example: Assuming API returns a list of concepts
for item in data:
subject_uri = URIRef(f"http://example.org/{item['id']}")
graph.add((subject_uri, RDFS.label, Literal(item['label'])))
graph.add((subject_uri, RDF.type, URIRef(f"http://example.org/{item['type']}")))
except requests.exceptions.RequestException as e:
print(f"API Ingestion Error: {e}")
Usage
my_graph = Graph()
ingest_api_data_to_graph('https://api.example.com/concepts', my_graph)
print(f"Graph now contains {len(my_graph)} triples.")
Step-by-step guide: This function demonstrates a secure pattern for ingesting live data from a REST API into a knowledge graph. It uses the `requests` library with a timeout to avoid hanging connections. The JSON response is parsed, and for each item, new triples (subject-predicate-object) are created in the RDF graph, dynamically building the semantic layer.
- Windows PowerShell for Log Analysis and AI Pipeline Monitoring
Verified Windows PowerShell commands for monitoring AI system logs:Get recent errors from the system log related to a hypothetical AI service Get-EventLog -LogName System -Source "AISemanticService" -EntryType Error -Newest 10 | Format-Table TimeGenerated, Message -Wrap Monitor a directory for new context files and calculate a hash Get-ChildItem "C:\AI\context_uploads\" -Filter .json | ForEach-Object { $hash = (Get-FileHash $<em>.FullName -Algorithm SHA256).Hash Write-Output "File: $($</em>.Name), SHA256: $hash" } Query a local Neo4j instance via PowerShell for health check Invoke-RestMethod -Uri "http://localhost:7474/db/data/" -Method Get | Select-Object bolt, neo4j_versionStep-by-step guide: These PowerShell commands are essential for operational oversight of an AI pipeline. The first command filters the System log for errors from a specific source. The second script block monitors a directory, generating SHA-256 hashes for new context files, which is critical for data integrity and security. The third command uses `Invoke-RestMethod` to perform a basic health check on a local Neo4j database.
-
Linux OS Hardening for AI Model and Data Repositories
Verified Linux bash commands for securing a server hosting AI assets:Harden SSH configuration sudo sed -i 's/PasswordAuthentication yes/PasswordAuthentication no/' /etc/ssh/sshd_config sudo sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin no/' /etc/ssh/sshd_config sudo systemctl restart sshd Configure firewall to allow only necessary ports (e.g., for API and DB) sudo ufw default deny incoming sudo ufw default allow outgoing sudo ufw allow 22/tcp SSH sudo ufw allow 7474/tcp Neo4j Bolt sudo ufw allow 8000/tcp AI API Port sudo ufw --force enable Set strict permissions on model and data directories sudo chown -R ai_user:ai_user /opt/ai_models/ sudo chmod -R 750 /opt/ai_models/ sudo find /opt/ai_data/ -type f -exec chmod 640 {} \;Step-by-step guide: This sequence of commands secures a Linux server. It disables password-based SSH authentication and root login, forcing key-based access. The Uncomplicated Firewall (UFW) is configured to block all incoming traffic except for specified, essential ports. Finally, it sets strict ownership and file permissions on directories containing sensitive AI models and data, preventing unauthorized read or write access.
-
Leveraging APOC Libraries in Cypher for Advanced Graph Analytics
Verified Cypher queries using APOC procedures for Neo4j:
// Find central, highly connected concepts in the knowledge graph
MATCH (c:Concept)
WITH c, size((c)--()) as degree
ORDER BY degree DESC
LIMIT 5
RETURN c.name, degree
// Use APOC to expand paths and find hidden relationships between AI concepts
MATCH (a:Concept {name:'Agentic AI'})
CALL apoc.path.expandConfig(a, {
relationshipFilter: "ENABLES|ENHANCED_BY",
maxLevel: 3
})
YIELD path
RETURN path
// Create a meta-graph of relationship types for schema analysis
CALL apoc.meta.graph() YIELD nodes, relationships
RETURN nodes, relationships;
Step-by-step guide: These Cypher queries utilize the APOC (Awesome Procedures on Cypher) library to perform advanced graph analytics. The first identifies the most interconnected “Concept” nodes. The second uses `apoc.path.expandConfig` to explore multi-hop relationships starting from “Agentic AI”, uncovering indirect connections. The third, apoc.meta.graph, provides a visual overview of the entire graph schema, which is invaluable for context engineering and understanding data topology.
What Undercode Say:
- Knowledge graphs are transitioning from static data repositories to dynamic reasoning engines that actively shape AI behavior and decision-making processes.
- The convergence of vector search and symbolic graph reasoning creates a hybrid architecture that is more resilient to hallucination and more capable of complex, multi-step problem-solving.
The shift from RAG to context engineering signifies a maturation of enterprise AI. It’s a move from merely providing data to an LLM to constructing a rich, structured, and actionable semantic understanding of an entire domain. This architecture forms the core of reliable Agentic AI, where autonomous agents can navigate complex information spaces, understand nuanced relationships, and make decisions based on a coherent model of the world, not just statistical word prediction. The technical implementation—combining graph databases, vector indices, and secure, automated pipelines—is the foundational work required to move beyond demos and into production-grade systems.
Prediction:
The semantic layer will become the most critical and contested component of the AI stack within the next 18-24 months. As Agentic AI moves into production, the organizations that have invested in building rich, well-engineered knowledge graphs will achieve a significant competitive advantage, enabling AI systems that demonstrate superior reasoning, accountability, and autonomy. This will lead to a new wave of cybersecurity focus on protecting these semantic layers from poisoning and extraction attacks, as they will embody the core intellectual property and operational logic of the business.
🎯Let’s Practice For Free:
IT/Security Reporter URL:
Reported By: Trey Rutledge – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅


