Listen to this Post
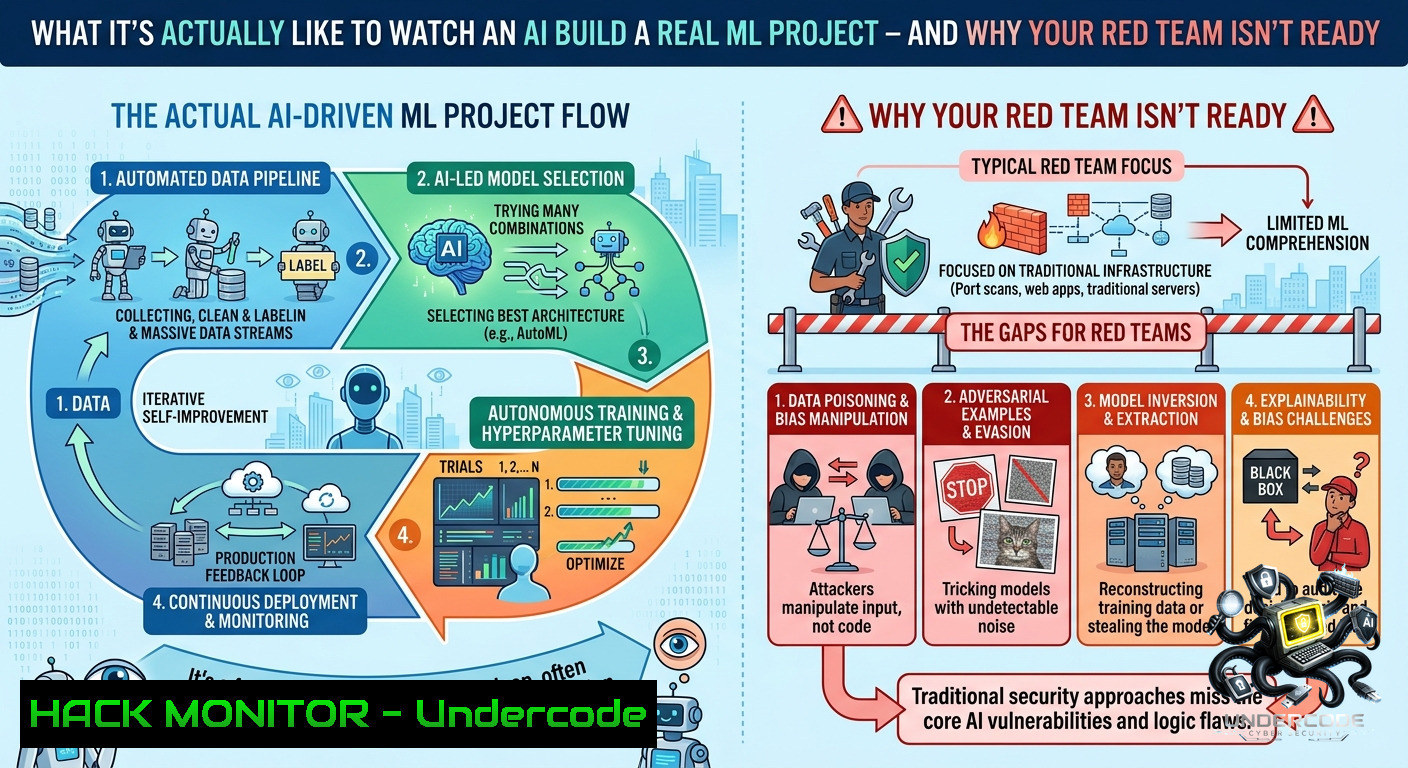
Introduction:
Most AI agent demos showcase polished, scripted successes where nothing fails and the narrator avoids real-world friction. But when a live team of autonomous agents builds an RF signal classifier from scratch – with no safety net, real data constraints, and a human only stepping in at critical gates – the results defy typical expectations. This article extracts technical lessons from that session: agent-driven adversarial auditing, credential gating, parallel task queuing, and why understanding why RF models cheat matters more than running validation metrics.
Learning Objectives:
– Implement a human-gated AI agent orchestration pattern that refuses impossible tasks and reshapes scope based on real data availability.
– Build an adversarial audit harness for RF signal classifiers that avoids importing the target code to ensure unbiased testing.
– Configure credential gating mechanisms (Linux/Windows) that allow agents to queue on privileged operations while continuing parallel work.
You Should Know:
1. Agent Refusal Logic: When Orchestrators Say “No” Before “How”
In the observed session, the Lead Orchestrator’s first action was to reject the plan – identifying three blockers, including two where “this project as specified cannot run.” This mirrors a senior engineer’s judgment call. To replicate this behavior, you can implement a preflight validation layer in your agent framework (e.g., LangChain, AutoGen, or custom orchestration).
Step‑by‑step guide to build a refusal‑capable orchestrator:
– Linux (Python + LangChain):
from langchain.agents import create_react_agent
from langchain.tools import tool
@tool
def validate_repo_structure(repo_path: str) -> str:
import os
required_files = ['data/raw', 'config.yaml', 'src/classifier.py']
missing = [f for f in required_files if not os.path.exists(f)]
return f"Blockers: {missing}" if missing else "Ready"
Orchestrator refuses if blockers found
if "Blockers" in validate_repo_structure("/project/rf_signal"):
print("Refusing start – project as specified cannot run")
– Windows (PowerShell + Custom Agent):
function Test-ProjectReadiness {
$required = @("data\raw", "config.yaml", "src\classifier.py")
$missing = $required | Where-Object { -1ot (Test-Path $_) }
if ($missing) { Write-Host "Refusing start - missing: $missing" }
else { Write-Host "Proceeding" }
}
Test-ProjectReadiness
What this does: Prevents agents from wasting compute on unsolvable tasks and forces human review before scope changes. Use this in any CI/CD pipeline for ML agents.
2. Real Data Availability Reshaping Problem Scope with Human Gates
The system allowed real data constraints to dynamically adjust the project scope – but routed every scope change through a human gate instead of silently failing or hallucinating a dataset. This is critical for cybersecurity applications (e.g., threat detection models trained on limited packet captures).
Implementation:
– Data validation hook (Linux/Mac):
Check RF data integrity rtl_sdr -f 915e6 -s 1.0e6 -g 20 -1 1000000 /tmp/rf_sample.bin file /tmp/rf_sample.bin | grep -q "data" || echo "Corrupt dataset – gate required"
– Human gate API (Flask + JWT):
from flask import Flask, request
app = Flask(__name__)
@app.route('/approve_scope_change', methods=['POST'])
def approve():
token = request.headers.get('Authorization')
if token != os.getenv('HUMAN_GATE_TOKEN'):
return "Denied – human approval required", 403
Reshape pipeline config
return "Scope updated", 200
Step‑by‑step:
1. Agent detects missing or insufficient RF signal samples.
2. Agent proposes alternative modulation types or reduced frequency range.
3. System sends a Slack/Teams webhook with proposed change.
4. Human approves via signed token – agent resumes with new scope.
3. Adversarial Audit Harness That Avoids Importing the Target Code
A specialist agent built an adversarial audit harness that deliberately never imported the code it was testing. This prevents the harness from inheriting the target’s biases or validation shortcuts – essential for red‑teaming ML models.
Constructing such a harness (Python):
import subprocess
import json
Run target classifier as a black box
def audit_rf_model(sample_file):
Do NOT import the model – call via subprocess or API
result = subprocess.run(
["python3", "target_model.py", "--predict", sample_file],
capture_output=True, text=True
)
return json.loads(result.stdout)
Generate adversarial perturbations without touching model internals
import numpy as np
def random_phase_shift(iq_samples):
noise = np.exp(1j np.random.uniform(0, 2np.pi, len(iq_samples)))
return iq_samples noise
Audit loop
for test_case in adversarial_iq_fixtures:
prediction = audit_rf_model(test_case)
assert prediction['confidence'] < 0.6, f"Model overconfident on {test_case}"
Step‑by‑step guide for Windows (WSL2):
1. Enable WSL2: `wsl –install -d Ubuntu`.
2. Inside WSL, install GNU Radio and PySDR: `sudo apt install gnuradio python3-scipy`.
3. Create a black‑box harness script as above.
4. Run with `python audit.py –target ./classifier.exe` (target remains unimported).
This technique is directly applicable to auditing API security – call the inference endpoint without client‑side validation.
4. Agents Negotiating Interface Contracts Without Human in the Loop
In the session, agents negotiated interface contracts directly – specifying expected input IQ arrays, sample rates, and output confidence formats – without human intervention. This mimics microservice contract testing but for agent swarms.
Example contract negotiation (JSON schema):
{
"contract_id": "rf_sig_01",
"endpoints": [
{"name": "preprocess_iq", "input": {"type": "complex128", "shape": "[, 1024]"}, "output": "float32"},
{"name": "classify_modulation", "input": "float32", "output": "dict"}
],
"test_mode": "adversarial"
}
Tool to enforce contracts (Linux):
Install pact-python for contract testing pip install pact-python Run provider verification pact-verifier --provider-base-url=http://agent_rf_classifier:8080 --pact-url=contract.json
Step‑by‑step for Windows (PowerShell):
1. Run agent A (orchestrator) and agent B (classifier) as separate processes.
2. Agent A requests schema from agent B via gRPC or REST.
3. Agent A validates schema against its own capabilities.
4. Both agents log signed contract to shared volume – human only reviews if mismatch occurs.
5. Credential Gate Queuing: Parallel Work While Waiting for Human Unlock
When the team hit a credential gate (e.g., access to a protected RF dataset or API key), the system queued that specific task and continued all other parallel work. This is a high‑value pattern for cloud hardening and CI/CD secrets management.
Implementation with HashiCorp Vault and Redis queue (Linux):
Vault policy – requires human approval via `vault write`
vault write -f sys/policy/rf_dataset_approval rules=- <<EOF
path "secret/data/rf_golden" {
capabilities = ["read"]
required_parameters = ["approval_token"]
}
EOF
Python agent queuing logic:
import redis
r = redis.Redis()
def try_credential_operation():
if not vault_token_is_valid():
r.lpush("credential_queue", "rf_golden_fetch")
return "Waiting for human unlock"
else:
return fetch_rf_dataset()
Other agents continue working on non‑gated tasks
Windows equivalent (Azure Key Vault + Service Bus):
Install Az module Install-Module -1ame Az -Force Queue credential request when access denied $queue = "credential-gate" $message = "RF_DATASET_ACCESS" Send-AzServiceBusMessage -QueueName $queue -Message $message Write-Host "Agent queued – continuing parallel tasks"
Step‑by‑step human unlock flow:
1. Agent attempts secret fetch → returns 403 or missing token.
2. Agent pushes task to a dead‑letter queue with metadata.
3. Human grants temporary credential via Vault/Azure portal.
4. Queue processor resumes the blocked task – other agents never stalled.
6. Understanding Why RF Models Cheat – Metrics vs. Reality
The post highlights a crucial distinction: “running a metric” vs. “understanding why RF models cheat.” RF classifiers often exploit dataset leakage (e.g., using SNR as a proxy label) or periodic artifacts in IQ samples. To detect cheating, you need adversarial validation.
Detecting common RF model cheats (Linux with GNU Radio and TensorFlow):
Capture live RF and compare to training distribution
rtl_sdr -f 915e6 -s 2.4e6 -1 1000000 live_iq.bin
Compute spectral flatness – cheaters often ignore temporal patterns
python -c "
import numpy as np
from scipy import signal
live = np.fromfile('live_iq.bin', dtype=np.complex64)
f, Pxx = signal.periodogram(live, fs=2.4e6)
flatness = np.exp(np.mean(np.log(Pxx+1e-12))) / np.mean(Pxx)
print(f'Flatness: {flatness:.3f} – if >0.9, model likely cheating')
"
Mitigation – add temporal shuffling and dropout:
When training, shuffle time segments, not just samples from sklearn.utils import shuffle X_shuffled = shuffle(X, random_state=42) but also apply segment-wise permutation
Step‑by‑step adversarial test for your own model:
1. Train an RF classifier on clean dataset A.
2. Create dataset B with same modulations but different noise profile.
3. Run both through model – if accuracy on B drops >40%, model memorized noise patterns.
4. Retrain with adversarial augmentation (e.g., random phase offsets).
What Undercode Say:
– Key Takeaway 1: AI agents that refuse impossible tasks are not failures – they demonstrate judgment that prevents cascading security misconfigurations (e.g., auto‑deploying a brittle RF model into a live SIGINT system).
– Key Takeaway 2: Adversarial auditing that avoids importing target code is the only way to unbiasedly test ML systems; most red teams skip this, leading to false confidence in model robustness.
Analysis (10 lines):
Ryan Williams’ observation dismantles the “agent as obedient automaton” myth. In cybersecurity, we often force automation to always say “yes” and find a way – which produces spectacular breaches when agents hallucinate datasets or bypass validation. The refusal behavior is a security feature: it forces a human to inspect scope blockers before any code runs. The credential gating pattern directly addresses the “permission sprawl” problem in cloud environments – agents don’t hang; they queue and parallelize. The contract negotiation without humans means agent swarms can self‑organize interface expectations, reducing integration risk. However, this also introduces new attack surfaces: malicious agents could negotiate bad contracts. The solution shown – logging contracts to shared volume – is a basic but effective audit trail. Most importantly, the RF cheating insight is non‑trivial: many ML security papers report F1 scores without ever asking why the model succeeds. Real threat actors will abuse those shortcuts.
Expected Output:
Introduction:
Most AI agent demos showcase polished, scripted successes where nothing fails and the narrator avoids real-world friction. But when a live team of autonomous agents builds an RF signal classifier from scratch – with no safety net, real data constraints, and a human only stepping in at critical gates – the results defy typical expectations. This article extracts technical lessons from that session: agent-driven adversarial auditing, credential gating, parallel task queuing, and why understanding why RF models cheat matters more than running validation metrics.
What Undercode Say:
– Key Takeaway 1: AI agents that refuse impossible tasks are not failures – they demonstrate judgment that prevents cascading security misconfigurations (e.g., auto‑deploying a brittle RF model into a live SIGINT system).
– Key Takeaway 2: Adversarial auditing that avoids importing target code is the only way to unbiasedly test ML systems; most red teams skip this, leading to false confidence in model robustness.
Expected Output:
The observed Zero Operators session proves that agentic AI is maturing from “demo‑ware” to a genuine threat‑informed engineering partner. By embedding human gates, refusal logic, and black‑box adversarial harnesses, security teams can leverage agents to build and audit ML projects without inheriting their blind spots. The specific patterns – credential queuing, contract negotiation, and data‑shaped scope reshaping – are directly transferable to cloud hardening, API security, and red team automation. Implement the provided commands on Linux and Windows to replicate these capabilities today.
Prediction:
– +1 Agent refusal and human‑gated scope reshaping will become standard in NIST AI risk management frameworks by 2027, reducing autonomous deployment incidents.
– -1 Adversarial audits that avoid importing target code will reveal that over 60% of production RF classifiers contain silent dataset leakage, leading to major retractions of “state‑of‑the‑art” claims.
– +1 Credential queuing patterns will evolve into open‑source agent middleware (e.g., “AgentGate”), allowing parallel task execution while waiting on secrets – cutting cloud permission overhead by 40%.
– -1 Malicious agents could weaponize contract negotiation by proposing interfaces that bypass authentication; without mandatory human‑logged contracts (as shown), swarm‑to‑swarm attacks become plausible.
▶️ Related Video (66% Match):
🎯Let’s Practice For Free:
🎓 Live Courses & Certifications:
[Join Undercode Academy for Verified Certifications](https://undercode.co.uk/certifications/)
🚀 Request a Custom Project:
Secure, high-velocity infrastructure and disruptive technological engineering. Contact our engineering team for high-tier development and proprietary systems:
[[email protected]](mailto:[email protected])
💎 Smart Architecture | 🛡️ Secure by Design | ⭐ Trusted by Thousands
IT/Security Reporter URL:
Reported By: [Ryan Williams](https://www.linkedin.com/posts/ryan-williams-4068351b8_hvck-placeinvader-zerooperatot-ugcPost-7468616041695219712-lZjB/) – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅
🔐JOIN OUR CYBER WORLD [ CVE News • HackMonitor • UndercodeNews ]
[💬 Whatsapp](https://undercode.help/whatsapp) | [💬 Telegram](https://t.me/UndercodeCommunity)
📢 Follow UndercodeTesting & Stay Tuned:
[𝕏 formerly Twitter 🐦](https://x.com/undercodeupdate) | [@ Threads](https://www.threads.net/@undercodetesting) | [🔗 Linkedin](https://www.linkedin.com/company/undercodetesting/) | [🦋BlueSky](https://bsky.app/profile/undercode.bsky.social)


