Listen to this Post
Introduction:
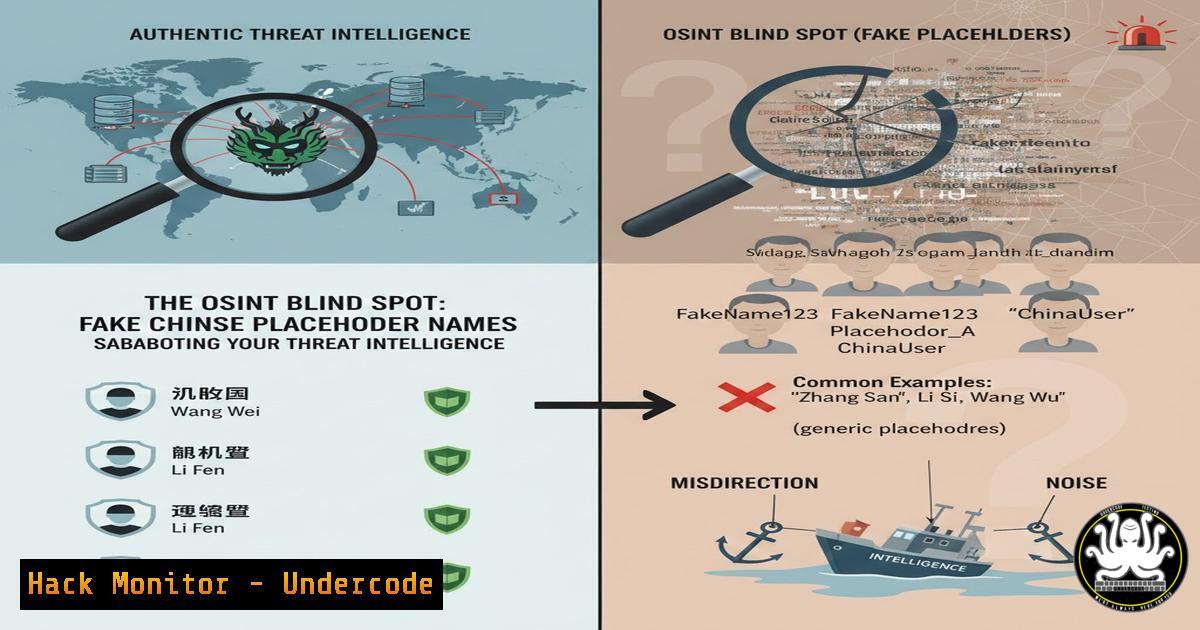
In the high-stakes world of Open-Source Intelligence (OSINT) and cyber threat investigations, data validity is everything. A critical, often overlooked vulnerability lies in the misinterpretation of placeholder names within Chinese-language documents and datasets. Failing to identify these non-existent personas can lead investigators down false trails, waste invaluable resources, and corrupt the foundation of intelligence analysis. This guide dissects the patterns of these placeholders and arms you with the technical methodologies to filter them out.
Learning Objectives:
- Identify the four primary patterns of fake Chinese names in documents and data streams.
- Implement automated technical checks using regex and data validation scripts.
- Integrate name verification steps into your OSINT collection and threat intelligence pipeline.
- Understand the operational security (OPSEC) risks of acting on intelligence containing placeholder data.
- Apply similar data sanitization principles to global datasets to improve overall intelligence fidelity.
You Should Know:
- Decoding the Placeholder Lexicon: Zhang San, Li Si, and Wang Wu
The most fundamental placeholders are the Chinese equivalents of “John Doe”: 张三 (Zhāng Sān), 李四 (Lǐ Sì), and 王五 (Wáng Wǔ). These names are ubiquitously used in examples, legal documents, software demos, and test databases. Treating them as real entities immediately invalidates an investigative thread.
Step-by-step guide:
- Create a Denylist: The first step is to establish a foundational denylist. This should be a simple text file or a list within your script.
placeholder_names_denylist.txt 张三 李四 王五
- Implement a Basic Filter: Use command-line tools like `grep` to filter out documents containing these names.
Linux/macOS: Check if a document contains a known placeholder grep -F -f placeholder_names_denylist.txt suspect_document.txt If output is generated, the document likely contains test data.
- Python Script for Batch Processing: For automated pipelines, use a simple Python script.
import re denylist = ["张三", "李四", "王五"] def check_document(text): for name in denylist: if name in text: print(f"[!] Placeholder detected: {name}") return False return True Usage with file reading with open("data_batch.txt", "r", encoding="utf-8") as f: if check_document(f.read()): print("[+] Document passed initial placeholder check.") -
The Redaction Flag: Identifying the “某” (Mǒu) Character
The character 某 (mǒu) meaning “a certain” or “some” is a formal redaction indicator. A name like “张某某” (Zhāng Mǒu Mǒu) or “李某” (Lǐ Mǒu) confirms a real person exists, but their full identity has been intentionally obscured in the document. This is crucial for understanding the context of your intelligence—you know you’re dealing with a redacted real entity, not test data.
Step-by-step guide:
- Pattern Recognition: Understand the patterns: `
+ 某` (e.g., 王某) or `[bash] + 某某` (e.g., 赵某某).</li> <li>Targeted Regex Search: Use regular expressions to find these patterns without flagging every instance of the character. [bash] Using grep with Perl-compatible regex grep -P '(?:张|李|王|赵|刘|陈|杨|黄|etc.)某+' chinese_corpus.txt
Note: The surname list should be expanded.
-
Script for Context Extraction: Develop a script that not only flags but extracts the context around the redaction for further analysis.
import re redaction_pattern = re.compile(r'([\u4e00-\u9fff]{1,3})某+') text = "涉案人员王某与嫌疑人李某某于次日会面。" matches = redaction_pattern.findall(text) if matches: print(f"[!] Redacted surname(s) found: {matches}") Output: [!] Redacted surname(s) found: ['王', '李'] -
The Synthetic Pattern: Surname + Number (e.g., 张1, 李2)
This pattern is a hallmark of system-generated test data, dummy databases, or software UI examples. Names like “张1”, “测试2”, or “李三1” are clear indicators of non-human, synthetic entries. Acting on intelligence containing these is a critical error.
Step-by-step guide:
- Construct a Regex for Synthetic Names: The pattern is typically a Chinese character followed by a digit or a sequence of digits.
Regex: A Chinese character followed directly by one or more digits. [\u4e00-\u9fff]\d+
- Integrate into Data Cleaning Workflow: Use this regex in data preprocessing, especially before loading data into analysis platforms like Maltego, Splunk, or Elasticsearch.
import pandas as pd import re df = pd.read_csv("chinese_users.csv") synthetic_pattern = re.compile(r'^[\u4e00-\u9fff]\d+$') Flag synthetic names in a 'name' column df['is_synthetic'] = df['name'].apply(lambda x: bool(synthetic_pattern.match(str(x)))) clean_df = df[~df['is_synthetic']] print(f"Filtered out {len(df) - len(clean_df)} synthetic entries.")
4. Sequential Placeholder Detection in Datasets
When you encounter lists of names like 测试一 (Test One), 测试二 (Test Two), or 张三, 李四, 王五 sequentially in a single document or database column, it is a definitive signature of a sample or test dataset. This is common in leaked database dumps where real data is mixed with developer samples.
Step-by-step guide:
- Visual & Programmatic Scanning: Manually scanning lists is the first step. For automation, check for sequences.
- Sequence Detection Logic: Write logic to detect known placeholder sequences in order.
common_sequences = [ ["张三", "李四", "王五"], ["测试一", "测试二", "测试三"], ["用户1", "用户2", "用户3"] ] def detect_sequence(names_list): for seq in common_sequences: Check if the sequence appears consecutively in the list for i in range(len(names_list) - len(seq) + 1): if names_list[i:i+len(seq)] == seq: print(f"[!] Common placeholder sequence detected: {seq}") return True return False sample_data = ["小明", "张三", "李四", "王五", "小红"] detect_sequence(sample_data) Triggers alert
5. Building an Automated OSINT Pre-Processing Pipeline
The ultimate goal is to integrate these checks into your automated intelligence gathering workflows to sanitize data at the point of ingestion.
Step-by-step guide:
- Tool Selection: Use a flexible tool like `Python` with libraries such as `pandas` and
re, or integrate filters into data collection tools like `OSINT-Framework` collectors, `SpiderFoot` modules, or `Shodan` post-processors.
2. Pipeline Design:
Stage 1 (Collection): Raw data from scrapers, APIs, or feeds.
Stage 2 (Sanitization): Run data through the series of filters outlined above (Denylist, 某-check, Synthetic Pattern, Sequence Detection).
Stage 3 (Flagging): Data flagged as containing placeholders is routed to a “low-fidelity” review queue.
Stage 4 (Analysis): Cleaned data proceeds to your primary threat intelligence and analysis platform.
3. Example Pipeline Snippet:
Pseudocode for an automated pipeline function
def osint_sanitizer_pipeline(raw_text, source_id):
checks = {
"common_placeholder": check_denylist(raw_text),
"redaction": find_redactions(raw_text),
"synthetic": find_synthetic_names(raw_text),
"sequence": detect_sequence_in_text(raw_text)
}
if any(checks.values()):
log_to_review_queue(source_id, raw_text, checks)
return None Exclude from primary analysis
else:
return clean_and_normalize(raw_text) Pass forward
What Undercode Say:
- Garbage In, Gospel Out: The gravest risk in intelligence is not a lack of data, but acting with high confidence on low-fidelity data. Placeholder names transform your sophisticated threat model into a house of cards. The technical controls to filter them are simple; the discipline to implement them systematically is what separates professional intelligence operations from amateur research.
- Context is King: Distinguishing between a redacted real person (王某) and a synthetic dummy (张1) dictates entirely different investigative actions. One may require deeper background checks or correlation with other redacted records, while the other requires immediate data source disqualification. This nuance must be encoded into your analysis logic.
Prediction:
As AI-generated synthetic data becomes more prevalent for training and testing, the volume and sophistication of placeholder “personas” in global datasets will explode. We will move beyond simple `Surname+Number` patterns to fully believable, AI-fabricated names, profiles, and digital footprints. The future frontline of OSINT will not just be finding information, but algorithmically verifying the authenticity of existence of entities in data. The techniques outlined here are the foundational skills for that coming fight; professionals who master data provenance and sanitization will be the only ones producing reliable intelligence. Failure to adapt will see organizations increasingly attacking phantom threats or, worse, missing real ones buried in noise.
▶️ Related Video (80% Match):
🎯Let’s Practice For Free:
IT/Security Reporter URL:
Reported By: Evaprokofiev Spotting – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅


