Listen to this Post
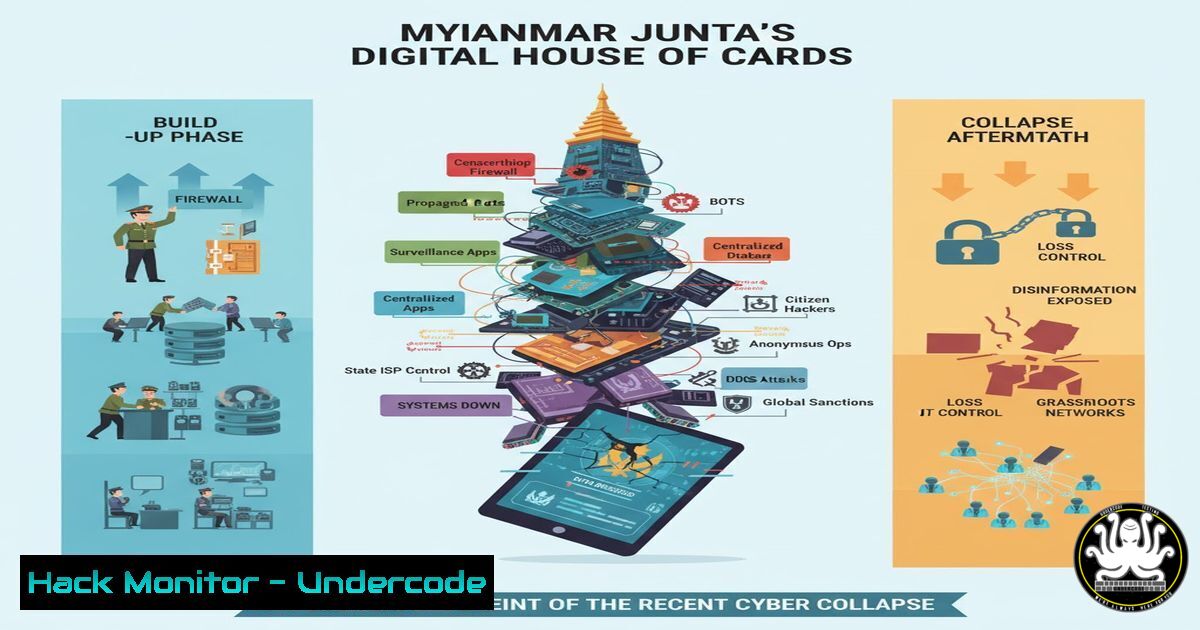
Introduction:
A catastrophic IT failure has crippled Myanmar’s state-operated infrastructure, exposing a fragile digital ecosystem vulnerable to both external attacks and internal neglect. This incident serves as a stark case study in the consequences of poor cybersecurity hygiene, inadequate system hardening, and a lack of skilled IT governance. The collapse of critical services, including airlines and government portals, reveals a blueprint of failure that organizations worldwide must learn from to fortify their own defenses against similar fates.
Learning Objectives:
- Decipher the critical system administration failures that lead to widespread service degradation.
- Master essential commands for hardening Linux and Windows servers against common attack vectors.
- Develop a proactive incident response and disaster recovery protocol to ensure business continuity.
You Should Know:
1. Linux Server Hardening and Integrity Checks
A compromised or unstable server is often the first domino to fall. These commands are vital for assessing system health and securing the base operating system.
Check for failed system services
systemctl --failed
Verify the integrity of system packages (Debian/Ubuntu)
dpkg --verify
Check for rootkits with rkhunter
rkhunter --check
List all open ports and associated processes
ss -tulnpe
Audit files for SUID/SGID bits (potential privilege escalation)
find / -type f ( -perm -4000 -o -perm -2000 ) -exec ls -l {} \;
Step-by-step guide:
Begin by checking `systemctl –failed` to identify any critical services that have crashed. Next, run `dpkg –verify` to look for discrepancies in installed packages, which could indicate unauthorized modification. The `rkhunter` scan will search for known rootkits, while `ss -tulnpe` provides a clear picture of all network listeners. Finally, the `find` command for SUID/SGID bits helps identify potentially dangerous executables that could grant elevated privileges.
2. Windows Server Security and Service Auditing
Windows-based infrastructure requires rigorous service and security policy auditing to prevent unauthorized access and ensure stability.
Get a list of all non-Microsoft services
Get-WmiObject Win32_Service | Where-Object {$<em>.PathName -notlike "Windows" -and $</em>.StartMode -eq "Auto"}
Check the status of the Windows Firewall
Get-NetFirewallProfile | Format-Table Name, Enabled
Audit user accounts and their group memberships
Get-LocalUser | Format-Table Name, Enabled, LastLogon
Get-LocalGroupMember Administrators | Format-Object Name, PrincipalSource
Check critical event logs for errors and warnings
Get-EventLog -LogName System -EntryType Error,Warning -Newest 50 | Format-Table TimeGenerated, EntryType, Source, Message -AutoSize
Verify Windows Defender status
Get-MpComputerStatus
Step-by-step guide:
Use the `Get-WmiObject` command to audit auto-starting, non-Microsoft services that could be points of failure. Immediately verify that the Windows Firewall is enabled across all profiles. Auditing local user accounts and, crucially, the members of the Administrators group, is essential for access control. Regularly review the System event log for hardware or OS-level errors, and confirm that Windows Defender is operational and its signatures are up to date.
3. Database Administration and Fortification
Database servers are high-value targets. Their stability and security are non-negotiable.
-- (MySQL) List all database users and their hosts SELECT user, host FROM mysql.user; -- (PostgreSQL) Check for active connections and their states SELECT datname, usename, state FROM pg_stat_activity; -- (General SQL) Review database processes for long-running queries SHOW PROCESSLIST;
Secure MySQL installation (remove test DB and anonymous users) mysql_secure_installation
Step-by-step guide:
After ensuring database connectivity, immediately audit user privileges with the `SELECT` query on `mysql.user` or `pg_stat_activity` to ensure no overly permissive or rogue accounts exist. Use `SHOW PROCESSLIST` to identify any queries that are locking tables or consuming excessive resources, which can cause application timeouts. Always run `mysql_secure_installation` on new MySQL deployments to remove default insecure configurations.
4. Web Server Configuration and SSL/TLS Auditing
Web front-ends are the public face of an organization and a primary attack surface.
Check Nginx/Apache configuration syntax nginx -t apache2ctl configtest Scan for SSL/TLS misconfigurations using testssl.sh testssl.sh your-domain.gov.mm Check for exposed .git or backup files curl -s http://target.com/.git/HEAD wget --spider http://target.com/db-backup.sql
Step-by-step guide:
Before restarting any web service, always run the configuration test (nginx -t or apache2ctl configtest) to avoid a full service stop due to a syntax error. Regularly audit your public-facing SSL/TLS configuration with a tool like `testssl.sh` to identify weak ciphers or expired certificates. Proactively scan your own domains for accidentally exposed version control directories or backup files using `curl` and wget.
5. Cloud Infrastructure and API Endpoint Security
Modern infrastructure relies on cloud and API components, which introduce new failure modes.
Use AWS CLI to check for publicly accessible S3 buckets aws s3api get-bucket-acl --bucket my-bucket-name Check for unauthenticated Azure Storage Blobs curl -I https://mystorageaccount.blob.core.windows.net/mycontainer Probe API endpoints for common security headers curl -I https://api.target.com/v1/endpoint | grep -i "strict-transport-security|x-frame-options|x-content-type-options"
Step-by-step guide:
For cloud storage, use the native CLI (aws s3api get-bucket-acl) to verify that access policies do not grant unintended public permissions. Simple `curl -I` commands can determine if a storage blob is accessible without authentication and if your API endpoints are returning crucial security headers like HSTS, which enforce HTTPS and prevent clickjacking.
6. Network Infrastructure Diagnostics
The network layer is the foundation of all digital services.
Continuous network monitoring with mtr (traceroute + ping) mtr -rwbc 10 your-server-ip Check for DNS resolution issues dig A your-domain.com dig NS your-domain.com Use nmap for a quick service discovery scan nmap -sV -T4 -F your-target-network
Step-by-step guide:
When facing intermittent connectivity issues, `mtr` is superior to a single `ping` as it provides a continuous, evolving view of the network path and packet loss. Always corroborate application errors with DNS checks using `dig` to rule out domain name resolution as the root cause. A rapid `nmap` scan can help rediscover what services are actually online across a network segment after a major outage.
7. Incident Response and Log Consolidation
A crisis is the wrong time to figure out your log locations. Centralize and analyze.
Tail the system log with real-time filtering for 'error' tail -f /var/log/syslog | grep -i error Search for authentication failures in the auth log grep "Failed password" /var/log/auth.log Use journalctl for deep systemd service introspection journalctl -u nginx.service --since "1 hour ago" -f
Step-by-step guide:
During an active incident, use `tail -f` on critical log files to monitor events in real time. Immediately search authentication logs for `Failed password` attempts to identify potential brute-force attacks. For services managed by systemd, `journalctl` is an indispensable tool, allowing you to follow the logs of a specific service (-u) from a specific time period (--since) to pinpoint the exact moment a failure began.
What Undercode Say:
- Technical Debt is a Silent Killer: The collapse was not a single-point failure but the inevitable result of accumulated technical debt—unpatched systems, poorly documented configurations, and a lack of defensive depth. Organizations must treat routine hardening and auditing with the same urgency as feature development.
- The Blurred Line Between Cyberattack and Systemic Failure: Without robust monitoring and logging, it is impossible to distinguish between a sophisticated cyberattack and a cascading internal failure. This ambiguity itself is a major risk, delaying an effective response and eroding stakeholder trust.
The Myanmar incident is a textbook example of an “accidental cyber disaster.” The root cause may well have been a simple misconfiguration or failed update in a critical system. However, in an environment lacking resilience—redundant systems, rollback capabilities, and skilled on-call personnel—that small trigger cascaded into a total service collapse. This creates a dangerous vacuum of information, allowing speculation about nation-state attacks to flourish, which further complicates the response. For global IT leaders, the lesson is that investing in fundamental operational excellence, cross-training, and disaster recovery is not merely about IT efficiency; it is a core strategic imperative for national and economic stability in the digital age.
Prediction:
The fallout from this event will accelerate a global reckoning on the resilience of critical national IT infrastructure. We predict a surge in regulatory pressure for mandatory cybersecurity and operational resilience frameworks for state-operated services, akin to financial sector regulations. Organizations that fail to publicly demonstrate a mature, auditable IT governance and disaster recovery strategy will face heightened scrutiny from partners, investors, and citizens, turning technical capability into a primary metric of institutional trustworthiness.
🎯Let’s Practice For Free:
IT/Security Reporter URL:
Reported By: Erinnordbywest Breaking – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅


