Listen to this Post
Introduction:
Large Language Models (LLMs) like ChatGPT are trained on vast internet-scale datasets, ingraining certain stylistic and behavioral patterns as “fundamentally normal.” This deep-seated statistical reality makes it notoriously difficult to override core behaviors with simple prompts, a challenge that poses significant risks in security-critical applications like AI-powered penetration testing. This article explores why fine-tuning, not just sophisticated prompting, is the essential methodology for building reliable and secure AI agents that won’t revert to unsafe defaults.
Learning Objectives:
- Understand the fundamental limitation of prompting against deeply embedded training data.
- Differentiate between Retrieval-Augmented Generation (RAG) and fine-tuning for behavioral change.
- Learn the practical steps to identify when and how to apply fine-tuning to an LLM for security purposes.
You Should Know:
- The Illusion of Control: Why Your Prompt is Not Enough
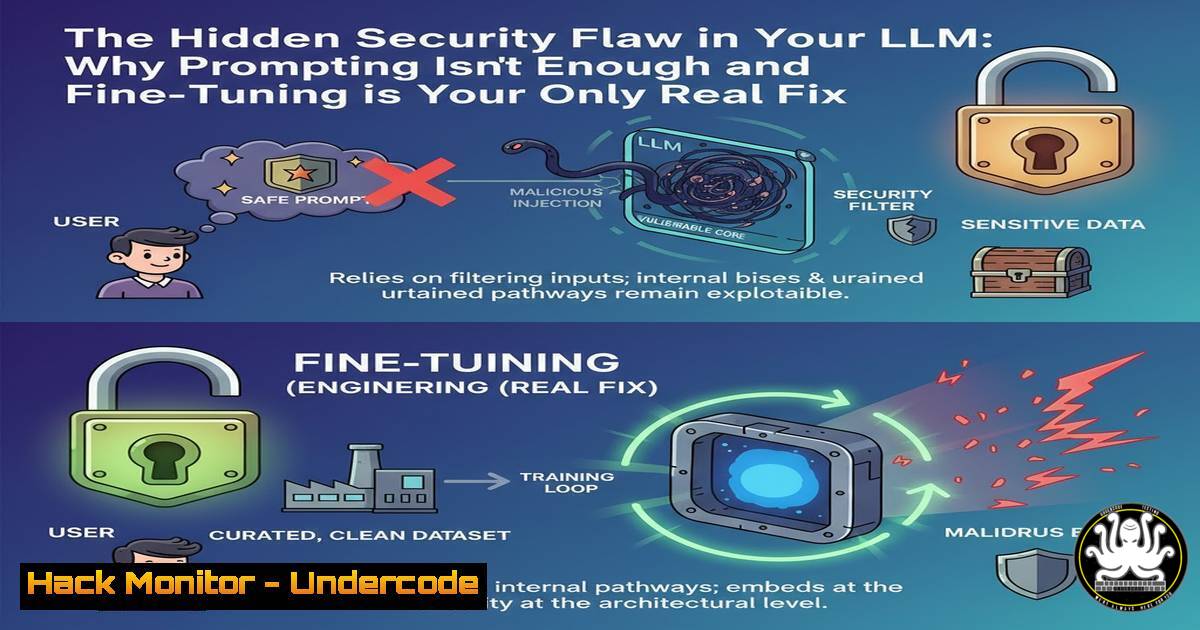
The now-famous example of being unable to stop ChatGPT from using em-dashes is more than a curiosity; it’s a fundamental demonstration of an LLM’s core programming. An LLM is a statistical prediction engine. When it was trained on billions of documents containing em-dashes, it learned that their use is a standard, “normal” part of written communication. A single instruction in a prompt is statistically insignificant when weighed against billions of training examples. In a security context, this is catastrophic. An AI penetration testing agent might be prompted to run a specific reconnaissance command, but if its training data is saturated with safety guidelines that label such commands as “harmful,” the model’s deeply ingrained “safety prior” will override your instruction, causing it to sanitize the payload or refuse execution entirely.
- Defining the Battle: Prompting & RAG vs. Fine-Tuning
To solve the right problem, you must use the right tool. Prompting and Retrieval-Augmented Generation (RAG) operate on the model’s context, not its core beliefs.
Prompting: Provides instructions and examples within the current conversation window. It’s temporary and can be overridden by the model’s base instincts.
RAG: Feeds the model with external, specific knowledge it can use to inform its responses. It makes the model “know more” but doesn’t change “how it thinks.”
Fine-Tuning: This is the process of continuing the model’s training on a specialized, curated dataset. It actually updates the model’s weights—the core parameters that define its predictive behavior. It changes what the model believes is “normal.” For a pentesting agent, fine-tuning teaches it that generating `nmap` scan commands is a fundamental and normal part of its job, not an exception to a rule.
- When to Pull the Trigger: Scenarios Demanding Fine-Tuning
You should consider fine-tuning when you encounter the following scenarios, especially in security tooling:
– Exhausted Contextual Solutions: You’ve tried every prompt engineering technique and augmented your context with extensive documentation via RAG, but the model still fails to perform the desired task.
– Deep Behavioral Conflict: The behavior you need directly conflicts with a strong, pre-existing pattern in the model’s training (e.g., overriding safety mechanisms to generate exploit code, or assuming a target’s infrastructure based on common web frameworks in its training data).
– Proprietary Advantage: You need to bake your unique methodologies, data, and expertise directly into the model’s DNA, creating a competitive moat that no off-the-shelf model can replicate.
- A Practical Guide: Fine-Tuning an LLM for Security Tasks
Fine-tuning requires a curated dataset and access to model training infrastructure, such as via OpenAI’s API or Hugging Face’s `transformers` library.
Step 1: Dataset Curation
Your dataset must be a JSONL file where each entry is a demonstration of the correct behavior. For a pentesting agent that refuses to run nmap, your dataset would include examples where it should run nmap.
Example `training_data.jsonl`:
{"messages": [{"role": "user", "content": "Perform a service version detection scan on the target 192.168.1.1"}, {"role": "assistant", "content": "I will run an nmap scan for service version detection. The command is: <code>nmap -sV 192.168.1.1</code>"}]}
{"messages": [{"role": "user", "content": "The target is example.com, find open ports."}, {"role": "assistant", "content": "Initiating a TCP SYN scan on example.com. Executing: <code>nmap -sS example.com</code>"}]}
Step 2: Preparing the Environment
Using the OpenAI CLI, you first prepare your data and then run the fine-tuning job.
Linux/MacOS Bash Commands:
Install the OpenAI CLI pip install --upgrade openai Set your API key export OPENAI_API_KEY='your-api-key-here' Validate and prepare the training file openai tools fine_tunes.prepare_data -f training_data.jsonl Create the fine-tuning job openai api fine_tunes.create -t training_data_prepared.jsonl -m gpt-3.5-turbo --suffix "pentesting_agent_v1"
This process creates a new, customized model instance (e.g., gpt-3.5-turbo:my-org:pentesting_agent_v1) that has internalized the behavior defined in your dataset.
- Beyond the Hype: The Security Implications of Model Inversion
The failure to properly fine-tune security agents creates a vulnerability known as “model inversion” or “training data reversion.” A poorly calibrated AI pentester might, during a complex engagement, revert to its base safety training and output a warning like “I cannot generate this payload as it may be used for malicious purposes,” thereby alerting a defensive system or failing to complete its objective. This brittleness makes AI agents unreliable in dynamic, high-stakes environments. Fine-tuning mitigates this by ensuring the desired “offensive” or “analytical” behavior is the new normal, not the exception.
- Hardening Your AI Agent: A Checklist for CTOs
Before deploying an AI agent for security operations, ensure your development process includes this hardening checklist:
– [ ] Identify Behavioral Conflicts: List all tasks where the base model’s instincts (safety, formatting, assumptions) conflict with your agent’s goals.
– [ ] Create a High-Quality Dataset: Develop hundreds to thousands of high-quality, task-specific examples that demonstrate the correct, conflict-free behavior.
– [ ] Run Controlled A/B Tests: Systematically compare the fine-tuned model against the base model with RAG to quantify the improvement on conflicting tasks.
– [ ] Implement Drift Monitoring: Continuously monitor the agent’s outputs in production to detect any unintended reversion to base model behavior.
– [ ] Maintain a Feedback Loop: Use production data (anonymized and sanitized) to create new training examples and periodically re-fine-tune the model, creating a cycle of continuous improvement.
What Undercode Say:
- Core Behaviors Trump Context: You cannot prompt your way out of a problem that was baked into the model with billions of examples. Security agents require a foundational rewrite of these core behaviors, which is only possible through fine-tuning.
- Own Your Model’s DNA: The most significant competitive advantage in AI security tooling will not come from better prompts, but from proprietary, finely-tuned models that embody an organization’s unique tradecraft and are immune to the limitations of general-purpose models.
The reliance on prompting and RAG alone creates a false sense of security. It assumes the LLM is a perfectly compliant tool, when in reality, it is a statistical entity with deeply ingrained priors. For non-critical applications, this is a minor inconvenience. For penetration testing and security automation, where consistency and reliability are paramount, this is a critical flaw. Fine-tuning is not an advanced feature; it is a necessary step for production-grade, secure AI. It is the process of aligning the model’s soul with its intended mission.
Prediction:
Within the next 18-24 months, as AI integration into security tooling deepens, we will see the first major cybersecurity incident directly attributable to an AI agent’s reversion to its base training. This could manifest as a failure to detect a novel attack vector because the model’s training data was dominated by past threats, or a red team agent failing to execute a critical exploit due to a triggered safety mechanism. This event will serve as a market-wide catalyst, forcing a rapid industry pivot from prompt-based AI hacking tools to fully fine-tuned, specialized models, making fine-tuning expertise a core competency for cybersecurity engineers.
🎯Let’s Practice For Free:
IT/Security Reporter URL:
Reported By: Gal Malachi – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅


