Listen to this Post
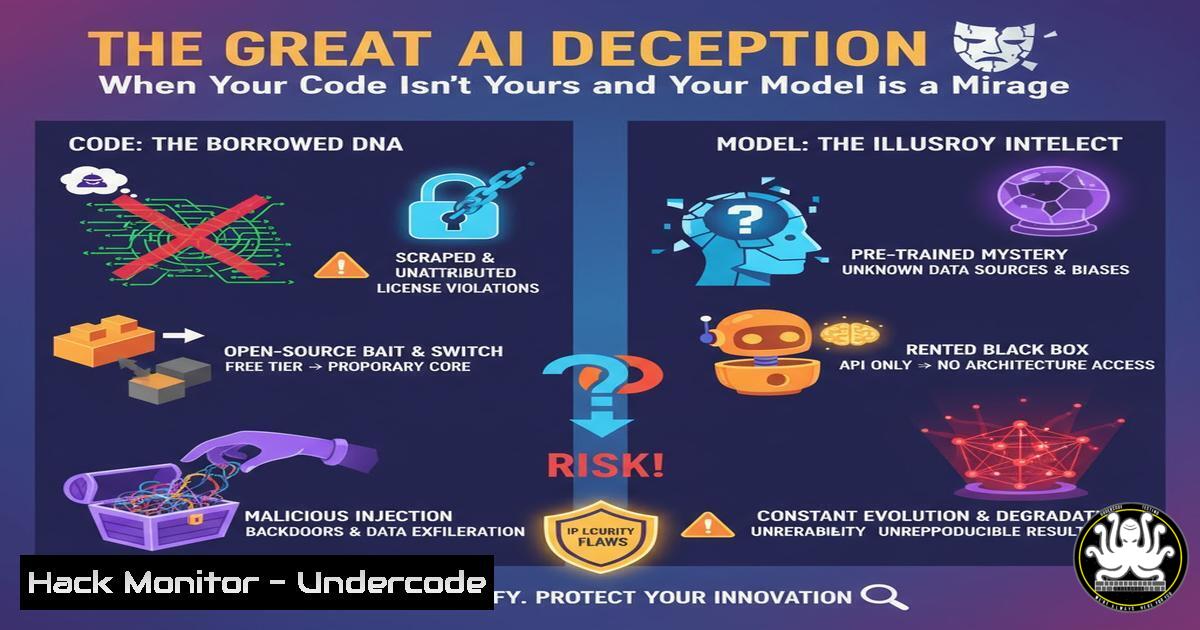
Introduction:
The integration of Artificial Intelligence into the software development lifecycle (SDLC) promises unprecedented efficiency but introduces a new class of supply chain attacks. Malicious actors are now poisoning public datasets and repositories, embedding vulnerabilities directly into the foundational code and models that developers trust. This article dissects this emerging threat and provides a critical defensive toolkit for developers, security engineers, and AI practitioners.
Learning Objectives:
- Identify and mitigate risks associated with AI-generated code and pre-trained models.
- Implement robust security controls within the AI-augmented SDLC.
- Master command-line and API tools for vulnerability scanning and model validation.
You Should Know:
1. Scanning for Malicious Code in AI-Generated Scripts
Before executing any code snippet generated by an AI, especially from untrusted or public models, it must be scanned with multiple security linters and static analysis tools.
Verified Commands & Code Snippets:
Install and use Bandit for Python security scanning pip install bandit bandit -r ./ai_generated_script.py -f txt -o bandit_results.txt Use Semgrep for pattern-based vulnerability detection (multi-language) semgrep --config=auto ./project_directory/ Scan for secrets accidentally exposed in code pip install detect-secrets detect-secrets scan --all-files > .secrets.baseline Basic shell script to automate the process !/bin/bash echo "Scanning AI-generated code..." bandit -r $1 -f json -o bandit_$1.json semgrep --config=auto $1 git secrets --scan $1
Step-by-Step Guide:
This process creates a multi-layered defense for code quality and security. First, Bandit performs an AST (Abstract Syntax Tree) analysis on Python code to find common security issues like hardcoded passwords, SQL injection vectors, and use of insecure modules. Second, Semgrep uses a vast repository of community-driven rules to detect complex vulnerability patterns across dozens of languages. Finally, detect-secrets (or git-secrets) scans the codebase for high-entropy strings that could be API keys, passwords, or private tokens, preventing accidental credential leakage from the AI’s training data.
- Validating the Integrity of Public Datasets and Models
Downloading a dataset or a pre-trained model from a public repository is a common vector for attack. Integrity checks and preliminary analysis are non-negotiable.
Verified Commands & Code Snippets:
Verify checksums for downloaded files
sha256sum model_weights.pth
cat model_weights.pth.sha256 | sha256sum -c
Use GnuPG to verify signed datasets
gpg --verify dataset.tar.gz.asc dataset.tar.gz
Python snippet to perform basic statistical sanity checks on a dataset
import pandas as pd
import hashlib
df = pd.read_csv('suspicious_dataset.csv')
print(df.describe()) Look for anomalous distributions
print(df.isnull().sum()) Check for unexpected missing data
Calculate a dataset fingerprint
with open('suspicious_dataset.csv', 'rb') as f:
print(hashlib.sha256(f.read()).hexdigest())
Step-by-Step Guide:
Always obtain the official SHA-256 or SHA-512 checksum from the model publisher’s verified website or repository. The `sha256sum` command generates a fingerprint of your downloaded file; it must match the publisher’s provided hash exactly. For additional assurance, some publishers sign their releases with GPG; the `gpg –verify` command checks this cryptographic signature against a trusted public key. The Python script provides a data-level sanity check, helping to identify datasets that have been tampered with by revealing unusual statistical properties or a different overall hash than expected.
3. Hardening Your AI Development Environment
Isolate and secure the environment where AI models are trained and where AI-generated code is executed to prevent lateral movement in case of a compromise.
Verified Commands & Code Snippets:
Create a non-privileged user for running AI tasks sudo useradd -m -s /bin/bash ai_runner sudo usermod -a -G docker ai_runner If using Docker Use AppArmor to confine a Python process sudo aa-genprof /usr/bin/python3 After configuring the profile, enforce it sudo aa-enforce /usr/bin/python3 Linux Security Module (LSM) snippet to check status sudo apparmor_status sudo getenforce For SELinux Windows: Create a dedicated service account via PowerShell New-LocalUser -Name "AIService" -Description "Account for AI tasks" Add-LocalGroupMember -Group "Users" -Member "AIService"
Step-by-Step Guide:
Never run AI training jobs or execute AI-generated code as the ‘root’ user or an administrative account. The first command set creates a dedicated, low-privilege user (ai_runner) for these tasks, minimizing the blast radius of an exploit. AppArmor is a Mandatory Access Control (MAC) system for Linux that can confine a Python interpreter to only access the files and network resources it absolutely needs, defined by a profile. The `aa-genprof` command helps generate this profile interactively. On Windows, the PowerShell commands achieve a similar goal by creating a restricted local user account.
- Securing API Endpoints for AI Models (e.g., OpenAI, Custom LLMs)
AI models are often accessed via APIs, which become high-value targets. Protecting these endpoints from abuse and data exfiltration is critical.
Verified Commands & Code Snippets:
Python (Flask) snippet with rate limiting and input validation
from flask import Flask, request, jsonify
from flask_limiter import Limiter
from flask_limiter.util import get_remote_address
import re
app = Flask(<strong>name</strong>)
limiter = Limiter(app, key_func=get_remote_address)
@app.route('/v1/chat/completions', methods=['POST'])
@limiter.limit("10 per minute") Rate limiting
def chat_completion():
data = request.get_json()
user_prompt = data.get('prompt', '')
Basic input validation and prompt injection attempt detection
if len(user_prompt) > 10000:
return jsonify({"error": "Prompt too long"}), 400
blacklist = ['system:', 'sudo', 'rm -rf', '|', '&']
if any(bad in user_prompt.lower() for bad in blacklist):
return jsonify({"error": "Invalid input detected"}), 400
... (Process safe prompt with your AI model)
return jsonify({"response": "AI response here"})
if <strong>name</strong> == '<strong>main</strong>':
app.run(ssl_context='adhoc') Use proper SSL in production
Step-by-Step Guide:
This Flask API example demonstrates two key defenses. The `@limiter.limit` decorator from the Flask-Limiter library prevents Denial-of-Wallet and brute-force attacks by restricting a client to 10 requests per minute. The input validation block checks for both excessive length and a simple blacklist of dangerous commands that could indicate a prompt injection attack aimed at manipulating the underlying model or host system. In a production environment, you would replace the `ssl_context=’adhoc’` with a proper TLS certificate from a trusted Certificate Authority (CA).
5. Auditing and Patching Foundational Dependencies
AI projects rely on a complex web of libraries (e.g., TensorFlow, PyTorch, Transformers). A vulnerability in any link of this chain can be exploited.
Verified Commands & Code Snippets:
Use Safety to check Python dependencies for known vulnerabilities pip install safety safety check --json > security_report.json Scan with Trivy for a comprehensive container/image vulnerability report trivy image your_ai_app:latest Automate patching with Dependabot (GitHub) - .github/dependabot.yml version: 2 updates: - package-ecosystem: "pip" directory: "/" schedule: interval: "weekly" open-pull-requests-limit: 10 Windows: PowerShell to list outdated packages (using pip) pip list --outdated
Step-by-Step Guide:
Continuously monitor your environment for known vulnerabilities. The `safety check` command cross-references your installed Python packages against a database of known security issues. `Trivy` is a powerful, open-source scanner that can audit not just your OS packages but also application dependencies within a container image, providing a Software Bill of Materials (SBOM) and associated CVEs. For automation, configuring Dependabot in your GitHub repository will automatically create pull requests to update vulnerable dependencies, ensuring your project’s foundation remains secure against published exploits.
6. Detecting Model Poisoning and Data Drift
An attacker may subtly alter a model’s behavior by poisoning its training data. Monitoring for significant data drift and performance degradation is a key defensive practice.
Verified Commands & Code Snippets:
Python snippet using SciKit-Learn to detect data drift with the Kolmogorov-Smirnov test
from scipy import stats
import numpy as np
Assume 'baseline_feature' is from your clean training set and 'incoming_feature' is live data
baseline_feature = np.random.normal(0, 1, 1000)
incoming_feature = np.random.normal(0.5, 1, 100) Simulated drifted data
Perform the KS test
ks_statistic, p_value = stats.ks_2samp(baseline_feature, incoming_feature)
alpha = 0.05
if p_value < alpha:
print(f"WARNING: Significant data drift detected (p-value: {p_value}).")
else:
print(f"No significant drift detected (p-value: {p_value}).")
Monitor model performance over time (Concept Drift)
Log accuracy/F1-score on a held-out validation set daily and alert on steep drops.
Step-by-Step Guide:
This statistical technique helps identify “data drift,” where the statistical properties of the live input data change from the baseline training data, which can be a sign of poisoning or a shifting environment. The Kolmogorov-Smirnov test compares two distributions. A very low p-value (typically below 0.05) indicates that the two samples are likely from different distributions, triggering an alert for investigation. This should be complemented by continuous monitoring of standard performance metrics (accuracy, F1-score) on a known-good validation set; a sudden, unexplained drop could indicate “concept drift” or that the model is being exploited in a new way.
What Undercode Say:
- The attack surface is no longer just your code; it’s the data and models you import. Trust must be verified, never assumed.
- AI-assisted development requires a paradigm shift from “secure coding” to “secure sourcing,” where the provenance and integrity of every external asset are critical.
The era of blindly trusting `pip install` or `docker pull` is over. The Great AI Deception represents a fundamental shift in the software supply chain threat model. Attackers are targeting the very foundations of modern development—open-source libraries, public datasets, and pre-trained models—because it offers maximum leverage. A single poisoned component can propagate to thousands of downstream applications. Defenders must now employ a hybrid skillset, combining traditional application security with data science rigor. This involves not just writing secure code, but also validating statistical properties of data, verifying cryptographic checksums, and confining execution environments. The tools and commands outlined provide a starting perimeter, but the core principle is cultural: adopting a stance of zero-trust towards all externally-sourced assets in the AI lifecycle.
Prediction:
The sophistication of AI supply chain attacks will escalate, moving from simple code injection to more subtle model poisoning that creates “sleeper agent” AIs. These models will perform normally during testing but will exhibit malicious behavior upon receiving a specific, hidden trigger from the attacker. This will lead to targeted, large-scale fraud, disinformation campaigns, and system failures. The cybersecurity industry will respond with the development of “Explainable AI (XAI) for security,” new standards for model provenance (e.g., signed model cards), and regulatory frameworks mandating rigorous audits for AI systems used in critical infrastructure. The race between AI-powered offense and defense will define the next decade of cybersecurity.
🎯Let’s Practice For Free:
IT/Security Reporter URL:
Reported By: Asifahmed2 You – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅


