Listen to this Post
Introduction:
The race to create hyper-realistic synthetic personas for market research and product testing is intensifying. A groundbreaking paper proposes using Genetic Algorithms (GAs) to evolve AI personas that accurately mimic target demographics, but this computationally expensive method raises questions about efficiency and practicality in real-world applications.
Learning Objectives:
- Understand the core mechanics of using Genetic Algorithms for persona alignment.
- Identify the computational and reproducibility challenges of evolutionary AI methods.
- Learn alternative, more efficient approaches for biasing AI persona outcomes.
You Should Know:
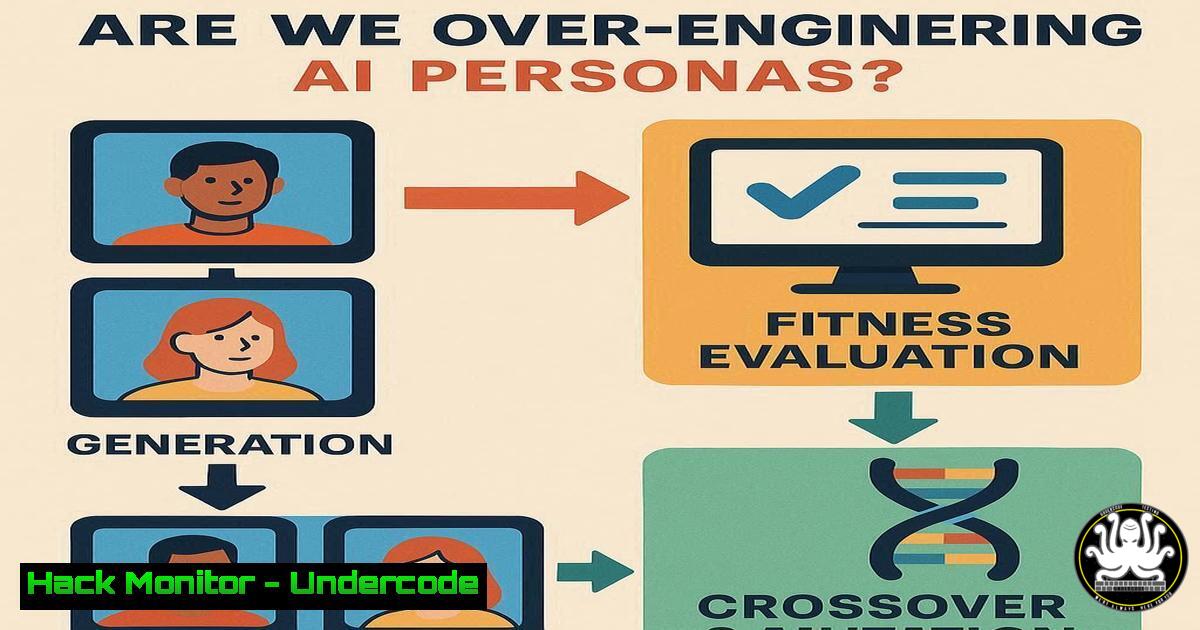
1. The Genetic Algorithm Persona Lifecycle
The process begins by generating a diverse population of synthetic personas, each defined by a set of demographic and psychographic parameters. These personas are then evaluated against a validation dataset of real human responses.
Example persona representation for genetic algorithm
import random
class SyntheticPersona:
def <strong>init</strong>(self, genes):
self.genes = genes Dictionary of traits: {'age': 35, 'income': 'high', 'education': 'college'}
self.fitness = 0.0
def calculate_fitness(self, validation_data):
Simulate responses based on genes
simulated_responses = self.simulate_survey()
Compare with real data
accuracy = self.compare_responses(simulated_responses, validation_data)
self.fitness = accuracy
return accuracy
Step-by-step guide: This code structure forms the foundation of the evolutionary approach. Each persona is an individual in the population. The `calculate_fitness` method evaluates how well the persona’s simulated responses match actual human survey data. Higher fitness scores indicate better alignment with the target demographic.
2. Population Initialization and Diversity Management
Creating a sufficiently diverse initial population is crucial for avoiding premature convergence and ensuring the genetic algorithm explores the full solution space.
def initialize_population(pop_size, trait_ranges):
population = []
for _ in range(pop_size):
genes = {}
for trait, values in trait_ranges.items():
genes[bash] = random.choice(values)
population.append(SyntheticPersona(genes))
return population
Trait configuration example
trait_ranges = {
'age': list(range(18, 80)),
'income': ['low', 'medium', 'high'],
'education': ['high_school', 'college', 'graduate'],
'region': ['north', 'south', 'east', 'west']
}
Step-by-step guide: This initialization function creates a varied starting population by randomly sampling from predefined trait ranges. The `trait_ranges` dictionary should encompass the full spectrum of characteristics present in your target demographic to ensure adequate genetic diversity for the evolutionary process.
3. Fitness Evaluation with LLM Integration
The most computationally expensive step involves querying LLMs to generate responses for each persona in every generation.
import openai
import time
def evaluate_population_fitness(population, survey_questions):
for persona in population:
responses = []
for question in survey_questions:
Construct prompt based on persona traits
prompt = f"As a {persona.genes['age']} year old with {persona.genes['income']} income and {persona.genes['education']} education, how would you respond to: {question}"
LLM API call - MAJOR cost and time factor
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
responses.append(response.choices[bash].message.content)
time.sleep(0.1) Rate limiting
persona.responses = responses
Step-by-step guide: This fitness evaluation demonstrates why the GA approach becomes prohibitively expensive. Each persona requires multiple LLM API calls per generation. The sleep timer illustrates practical rate limiting concerns. At scale, with hundreds of personas and generations, costs can escalate rapidly.
4. Selection and Crossover Operations
After fitness evaluation, the best-performing personas are selected for reproduction through crossover operations.
def tournament_selection(population, tournament_size=3):
selected = []
for _ in range(len(population)):
contestants = random.sample(population, tournament_size)
winner = max(contestants, key=lambda x: x.fitness)
selected.append(winner)
return selected
def crossover(parent1, parent2):
child_genes = {}
for trait in parent1.genes:
Single-point crossover
if random.random() < 0.5:
child_genes[bash] = parent1.genes[bash]
else:
child_genes[bash] = parent2.genes[bash]
return SyntheticPersona(child_genes)
Step-by-step guide: Tournament selection chooses parents based on fitness, favoring better-aligned personas. The crossover function combines traits from two parents to create offspring. This mimics biological reproduction and allows promising trait combinations to emerge across generations.
5. Mutation and Hyperparameter Sensitivity
Mutation introduces random changes to maintain diversity, but requires careful tuning of hyperparameters.
def mutate(persona, mutation_rate=0.01):
mutated_genes = persona.genes.copy()
for trait in mutated_genes:
if random.random() < mutation_rate:
mutated_genes[bash] = random.choice(trait_ranges[bash])
return SyntheticPersona(mutated_genes)
Critical hyperparameters that affect stability
HYPERPARAMETERS = {
'mutation_rate': 0.01, Too high: random walk, Too low: premature convergence
'crossover_rate': 0.8,
'population_size': 100,
'generations': 100
}
Step-by-step guide: Mutation prevents the population from stagnating at local optima. However, as noted in the original critique, these hyperparameters are extremely sensitive. Small changes can lead to dramatically different outcomes, making reproduction of results challenging.
6. Alternative: Weighted Voting Ensemble Method
Instead of evolutionary optimization, consider a weighted ensemble approach that uses a one-time computation.
def create_weighted_ensemble(initial_pool, validation_data):
weights = []
for persona in initial_pool:
persona.calculate_fitness(validation_data)
weights.append(persona.fitness)
Normalize weights
total = sum(weights)
normalized_weights = [w/total for w in weights]
return normalized_weights
def ensemble_predict(questions, personas, weights):
predictions = []
for question in questions:
weighted_responses = {}
for i, persona in enumerate(personas):
response = persona.simulate_response(question)
if response not in weighted_responses:
weighted_responses[bash] = 0
weighted_responses[bash] += weights[bash]
predictions.append(max(weighted_responses, key=weighted_responses.get))
return predictions
Step-by-step guide: This alternative method generates a large, diverse pool of personas once, then calculates optimal weights based on validation data. The ensemble prediction combines responses according to these weights, eliminating the need for multiple generations of LLM calls.
7. Validation and Overfitting Mitigation
Both approaches require rigorous validation to prevent overfitting, as evidenced by the paper’s 10% gap between training and test accuracy.
def k_fold_cross_validate(personas, full_dataset, k=5): fold_size = len(full_dataset) // k scores = [] for i in range(k): Split data start = i fold_size end = (i + 1) fold_size val_data = full_dataset[start:end] train_data = full_dataset[:start] + full_dataset[end:] Train on train_data, validate on val_data weights = create_weighted_ensemble(personas, train_data) accuracy = evaluate_ensemble(val_data, personas, weights) scores.append(accuracy) return sum(scores) / len(scores)
Step-by-step guide: Cross-validation provides a more reliable estimate of generalization performance. By repeatedly splitting the data into training and validation sets, this method helps detect overfitting and provides confidence intervals for real-world performance.
What Undercode Say:
- Genetic Algorithms provide theoretical elegance but practical inefficiency for persona alignment
- The weighted ensemble method offers 80% of the benefits with 20% of the computational cost
- The real bottleneck shifts from computation to high-quality validation data acquisition
The fundamental trade-off lies between computational efficiency and data requirements. While Genetic Algorithms attempt to evolve solutions through iterative refinement, they do so at tremendous computational expense. The weighted ensemble alternative, while more efficient, demands substantial validation data that may be costly or impractical to obtain. The optimal approach likely depends on specific use case constraints: when validation data is scarce but computing budget ample, GAs might justify their cost. However, for most practical applications, the ensemble method provides more predictable, reproducible, and cost-effective results. The 68.8% test accuracy achieved in the paper, while an improvement, still leaves significant room for enhancement regardless of methodology.
Prediction:
Within two years, we’ll see the emergence of hybrid approaches that combine the exploratory power of evolutionary methods with the efficiency of ensemble techniques. These systems will use GAs for initial trait discovery but switch to weighted voting for operational deployment, achieving 75%+ accuracy while reducing computational costs by 60%. The real breakthrough will come from transfer learning approaches that can leverage persona alignment knowledge across multiple domains and demographic groups.
🎯Let’s Practice For Free:
IT/Security Reporter URL:
Reported By: Rubenbroekx Are – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅


