Listen to this Post
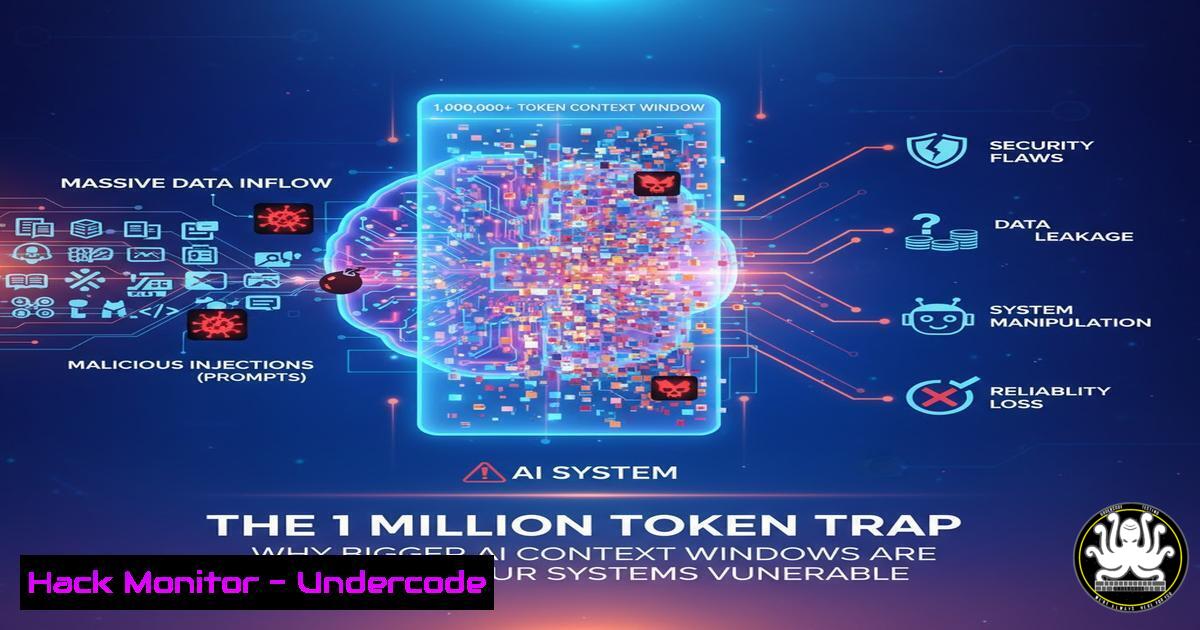
Introduction:
The AI industry is engaged in an arms race to deliver ever-larger context windows, with vendors touting 128k, 200k, and even 1 million token capacities as breakthrough features. However, new research reveals that this pursuit of massive context comes with significant costs—catastrophic accuracy drops beyond 50k tokens, 15x increased computational overhead for multi-agent systems, and alarming vulnerability to tool poisoning attacks that succeed 72.8% of the time. This article explores why context engineering, not context expansion, represents the future of production-grade AI systems.
Learning Objectives:
- Understand the performance and security tradeoffs of large context windows
- Implement four proven context engineering techniques (RAG, MCP, structured memory, compaction)
- Harden AI systems against tool poisoning and token-based attacks
- Optimize AI agent performance while minimizing computational costs
You Should Know:
1. The Context Window Performance Cliff
New research from Chroma demonstrates that model accuracy doesn’t just gradually decline with larger contexts—it falls off a cliff past 50k tokens. This occurs because models struggle to maintain attention coherence and relevant information retrieval across massive contexts. The “needle in a haystack” problem becomes exponentially worse as context grows.
Step-by-step guide explaining what this does and how to use it:
– Benchmark your model’s performance at different context sizes using evaluation frameworks
– Implement context length monitoring in your AI applications:
Python example for context monitoring
import tiktoken
def monitor_context_efficiency(text, model="gpt-4"):
encoding = tiktoken.encoding_for_model(model)
tokens = encoding.encode(text)
token_count = len(tokens)
efficiency_threshold = 50000 Chroma research threshold
if token_count > efficiency_threshold:
print(f"Warning: {token_count} tokens exceeds optimal threshold")
return False
return True
– Set hard limits on context sizes in production systems, rejecting requests beyond 50k tokens unless specifically authorized
2. Retrieval-Augmented Generation (RAG) Implementation
RAG solves the context problem by maintaining external knowledge bases and retrieving only relevant information at inference time. This reduces context window bloat while improving accuracy and reducing vulnerability surface.
Step-by-step guide explaining what this does and how to use it:
– Set up a vector database (Chroma, Pinecone, or Weaviate)
– Implement semantic search for relevant context retrieval:
from sentence_transformers import SentenceTransformer
import chromadb
class RAGSystem:
def <strong>init</strong>(self):
self.model = SentenceTransformer('all-MiniLM-L6-v2')
self.client = chromadb.Client()
self.collection = self.client.create_collection("knowledge_base")
def add_documents(self, documents):
embeddings = self.model.encode(documents)
self.collection.add(
embeddings=embeddings,
documents=documents,
ids=[f"doc_{i}" for i in range(len(documents))]
)
def query(self, question, n_results=3):
query_embedding = self.model.encode([bash])
results = self.collection.query(
query_embeddings=query_embedding,
n_results=n_results
)
return results['documents'][bash]
– Integrate retrieved context into your prompts, keeping total token count under 50k
- Model Context Protocol (MCP) for Secure Tool Integration
MCP provides a standardized framework for AI agents to interact with external tools and data sources securely. This prevents tool poisoning attacks by implementing strict access controls and validation layers.
Step-by-step guide explaining what this does and how to use it:
– Implement MCP servers for critical tool integrations:
Example MCP server for database queries
import mcp
import sqlite3
from typing import List
class DatabaseServer(mcp.Server):
def <strong>init</strong>(self):
super().<strong>init</strong>("database_server")
self.conn = sqlite3.connect('example.db')
@mcp.tool()
def query_database(self, query: str) -> str:
Validate query for safety
if self._validate_query(query):
cursor = self.conn.cursor()
cursor.execute(query)
return str(cursor.fetchall())
return "Query validation failed"
def _validate_query(self, query: str) -> bool:
dangerous_keywords = ['DROP', 'DELETE', 'UPDATE', 'INSERT']
return not any(keyword in query.upper() for keyword in dangerous_keywords)
server = DatabaseServer()
– Configure strict permission boundaries for each tool
– Implement comprehensive logging and audit trails for all tool usage
4. Structured Memory Systems
Instead of dumping unstructured context, structured memory organizes information into schematized data that AI agents can efficiently query and update. This reduces token waste and improves reasoning accuracy.
Step-by-step guide explaining what this does and how to use it:
– Design memory schemas based on your application needs:
from pydantic import BaseModel
from typing import Dict, List
class ConversationMemory(BaseModel):
user_preferences: Dict[str, str]
recent_interactions: List[bash]
known_facts: Dict[str, bool]
pending_actions: List[bash]
class MemoryManager:
def <strong>init</strong>(self):
self.memory = ConversationMemory(
user_preferences={},
recent_interactions=[],
known_facts={},
pending_actions=[]
)
def compress_interaction(self, interaction: str) -> str:
Extract key information and store in structured format
compressed = self._extract_key_points(interaction)
self.memory.recent_interactions.append(compressed)
Keep only recent interactions to prevent bloat
if len(self.memory.recent_interactions) > 10:
self.memory.recent_interactions.pop(0)
return compressed
– Implement memory compression routines that summarize and structure historical context
– Use graph databases for complex relationship tracking in agentic systems
5. Context Compaction Techniques
Context compaction algorithms automatically summarize, remove redundant information, and prioritize critical content to maintain context quality within optimal token ranges.
Step-by-step guide explaining what this does and how to use it:
– Implement semantic similarity detection to remove redundant information:
from sklearn.metrics.pairwise import cosine_similarity import numpy as np class ContextCompactor: def <strong>init</strong>(self, similarity_threshold=0.8): self.threshold = similarity_threshold def compact_context(self, context_chunks: List[bash]) -> List[bash]: if len(context_chunks) <= 1: return context_chunks embeddings = self.model.encode(context_chunks) similarity_matrix = cosine_similarity(embeddings) unique_chunks = [] used_indices = set() for i in range(len(context_chunks)): if i in used_indices: continue unique_chunks.append(context_chunks[bash]) Mark similar chunks as used for j in range(i+1, len(context_chunks)): if similarity_matrix[bash][j] > self.threshold: used_indices.add(j) return unique_chunks
– Implement importance scoring to prioritize critical context elements
– Use extractive summarization to reduce verbose sections while preserving key information
6. Tool Poisoning Defense Framework
With tool poisoning attacks succeeding 72.8% of the time, implementing robust defense mechanisms is critical for production AI systems.
Step-by-step guide explaining what this does and how to use it:
– Implement tool output validation and sanitization:
class ToolSecurityLayer:
def <strong>init</strong>(self):
self.sandbox = SandboxEnvironment()
def safe_tool_execution(self, tool_call: str, parameters: dict) -> str:
Validate tool call signature
if not self._validate_tool_signature(tool_call, parameters):
raise SecurityException("Invalid tool signature")
Execute in sandbox
result = self.sandbox.execute(tool_call, parameters)
Sanitize output
sanitized_result = self._sanitize_output(result)
Log for audit
self._audit_log(tool_call, parameters, sanitized_result)
return sanitized_result
def _sanitize_output(self, result: str) -> str:
Remove potential injection payloads
import re
patterns = [
r'<script.?</script>',
r'javascript:',
r'vbscript:',
r'onload=',
r'onerror='
]
sanitized = result
for pattern in patterns:
sanitized = re.sub(pattern, '[bash]', sanitized, flags=re.IGNORECASE)
return sanitized
– Implement mandatory tool execution timeouts
– Create tool-specific allowlists and behavior profiles
7. Multi-Agent System Token Optimization
Multi-agent systems burn 15x more tokens for marginal gains due to inefficient inter-agent communication and redundant processing. Strategic optimization can reduce this overhead significantly.
Step-by-step guide explaining what this does and how to use it:
– Implement agent communication protocols that minimize token usage:
class EfficientMultiAgentSystem:
def <strong>init</strong>(self):
self.agents = {}
self.communication_bus = MessageBus()
def coordinate_agents(self, task: str) -> str:
Route task to most appropriate agent first
primary_agent = self._route_to_primary_agent(task)
primary_result = primary_agent.process(task)
Only involve secondary agents if necessary
if self._requires_specialized_processing(primary_result):
secondary_agent = self._route_to_specialist(primary_result)
secondary_result = secondary_agent.refine(primary_result)
return secondary_result
return primary_result
def _route_to_primary_agent(self, task: str) -> Agent:
Simple routing logic - implement more sophisticated in production
if "analyze" in task.lower():
return self.agents["analyst"]
elif "create" in task.lower():
return self.agents["creator"]
else:
return self.agents["generalist"]
– Implement agent result caching to avoid redundant processing
– Use distilled communication protocols that exchange essential information only
– Monitor inter-agent communication volume and optimize routing logic
What Undercode Say:
- Context Engineering Over Context Expansion: Production AI systems require careful context management, not just larger windows. The 50k token threshold identified by Chroma research should serve as a practical guideline for most applications.
- Security Cannot Be an Afterthought: With tool poisoning attacks achieving 72.8% success rates, security must be integrated into the context engineering process from the beginning through validation layers, sandboxing, and comprehensive audit trails.
The race for massive context windows represents a fundamental misunderstanding of how production AI systems should be architected. While vendors compete on token counts, practical implementations show that context quality, not quantity, determines system reliability and security. The four techniques outlined—RAG, MCP, structured memory, and compaction—provide a framework for building AI systems that are not only more efficient but also fundamentally more secure. As AI continues to integrate into critical business processes, the shift from context expansion to context engineering will separate successful implementations from costly failures.
Prediction:
The next 18-24 months will see a dramatic shift in enterprise AI strategy from pursuing maximum context windows to implementing sophisticated context engineering frameworks. We’ll see the emergence of Context Engineering as a dedicated discipline within AI development, with specialized tools and best practices. Security concerns around tool poisoning and prompt injection will drive adoption of standardized protocols like MCP, while performance requirements will make context compaction and structured memory standard features in enterprise AI platforms. The vendors who win in this space won’t be those with the largest context windows, but those providing the most efficient and secure context management capabilities.
🎯Let’s Practice For Free:
IT/Security Reporter URL:
Reported By: Rocklambros Contextengineering – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅


