Listen to this Post
Introduction:
The fusion of large language models (LLMs) with real-time voice AI is revolutionizing human-computer interaction, moving beyond simple chatbots to dynamic, conversational agents. A recent project, an unofficial “Starbucks AI Barista” named Riya, demonstrates this power by leveraging a local LLM for privacy and a sophisticated voice pipeline for a seamless user experience. This architecture not only showcases innovation but also highlights critical considerations for deploying secure and efficient AI systems.
Learning Objectives:
- Understand the end-to-end architecture of a modern voice AI agent, including component integration.
- Learn the benefits and configuration of running an LLM locally using Ollama for enhanced data privacy.
- Identify potential security vulnerabilities in AI voice pipelines and implement basic hardening measures.
You Should Know:
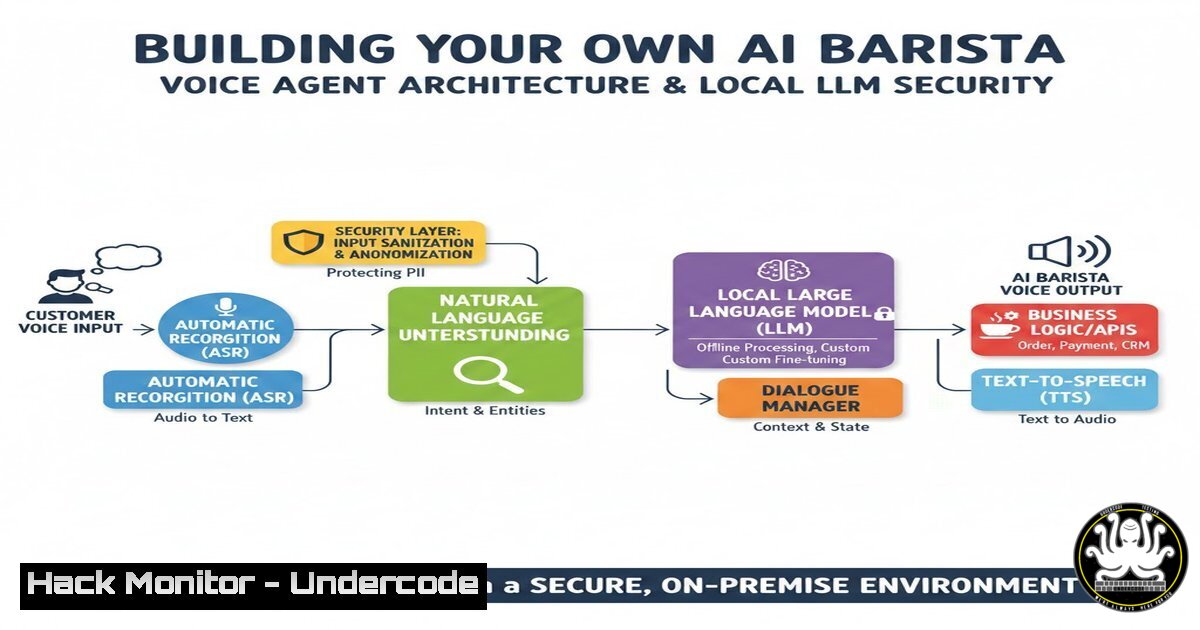
- The Core Architecture: A Symphony of Specialized Services
This AI Barista isn’t a single monolithic application but a distributed system where each component handles a specific task. The frontend, built with a web framework, acts as the user interface. The real magic happens in the backend, which integrates several APIs. The voice input from a user is captured and sent to Deepgram’s Nova-3 model for speech-to-text (STT). This transcribed text is then passed to the core “brain”—the Gemma3 12B model running locally via Ollama. Ollama acts as a local server, managing the LLM and processing the prompts. The generated text response is then sent to Murf AI’s API, which converts it back into natural-sounding speech using the “Natalie” voice. LiveKit, a real-time communication platform, acts as the “transport” layer, efficiently managing the WebSocket connections and data flow between the frontend and backend services, ensuring low-latency interaction.
- Local LLM Deployment with Ollama: Privacy and Control
Running the Gemma3 model locally via Ollama is a pivotal security and privacy decision. By processing the core conversation logic on-premises, the developer ensures that sensitive data, like voice orders and potential personal details, never leaves the local machine. This mitigates the risk of data breaches at the third-party API level. Ollama simplifies the process of pulling and running open-source models.
Step-by-Step Guide:
- Install Ollama: Visit the official Ollama website (https://ollama.ai) and download the appropriate version for your operating system (Windows, macOS, or Linux).
- Pull the Model: Open your terminal or command prompt and run the command to download the Gemma3 12B model. `ollama pull gemma2:12b`
3. Run the Model: Start the model as a server. By default, Ollama’s API runs onlocalhost:11434. `ollama run gemma2:12b`
4. Verify Installation: You can test the API endpoint usingcurl. `curl http://localhost:11434/api/chat -d ‘{“model”: “gemma2:12b”, “messages”: [{ “role”: “user”, “content”: “Hello” }]}’`
This local endpoint is what the AI Barista’s backend code would call, instead of a cloud-based LLM API like OpenAI.
3. The Voice Pipeline: Securing API Endpoints
While the LLM is local, the voice synthesis (Murf AI) and speech recognition (Deepgram) components are typically cloud-based services. This hybrid model requires careful API key management.
Step-by-Step Guide for Secure Key Handling:
- Never Hardcode Keys: Avoid pasting API keys directly into your source code.
- Use Environment Variables: Store sensitive keys in environment variables.
Linux/macOS: Add to your `~/.bashrc` or `~/.zshrc` file: `export DEEPGRAM_API_KEY=’your_key_here’`export MURF_AI_KEY='your_key_here'
Windows (PowerShell): Use `$env:DEEPGRAM_API_KEY = ‘your_key_here’`
- Access in Python Code: Read these variables securely in your application.
import os deepgram_key = os.environ.get('DEEPGRAM_API_KEY') murf_key = os.environ.get('MURF_AI_KEY') - Implement Rate Limiting: Add logic to your backend to prevent excessive calls to these paid APIs, which could lead to bill shocks or denial-of-service.
4. Real-Time Communication with LiveKit: Network Hardening
LiveKit handles the real-time audio stream. Ensuring this connection is secure is paramount to prevent eavesdropping or man-in-the-middle attacks.
Step-by-Step Guide:
- Enforce WSS: Ensure your frontend code connects to the LiveKit server using `wss://` (WebSocket Secure) and not `ws://` (unencrypted).
- Secure Your LiveKit Server: If self-hosting LiveKit, follow its security documentation. This includes using strong secrets, configuring CORS properly, and keeping the server updated.
- Authentication: Use secure tokens for user authentication with LiveKit. Do not use weak or easily guessable API keys/secrets in client-side code.
5. Frontend Security: Protecting the User Interface
The web frontend is the first point of contact for the user and must be secured against common web vulnerabilities.
Step-by-Step Guide:
- Input Validation: While Deepgram handles voice, ensure any secondary text inputs are sanitized to prevent Cross-Site Scripting (XSS) attacks.
- Content Security Policy (CSP): Implement a strict CSP header in your web server configuration to prevent the execution of unauthorized scripts.
- Keep Dependencies Updated: Regularly update all frontend libraries and frameworks to patch known vulnerabilities. Use tools like `npm audit` if using Node.js.
What Undercode Say:
- Local LLMs are a Game-Changer for Privacy-Critical Applications. By processing the conversational core locally, developers can build AI agents for healthcare, finance, or personal assistants without the inherent risk of sending sensitive data to a third party.
- The “Hybrid AI” Model is the Pragmatic Present. Combining local LLMs with specialized cloud APIs for specific tasks (like high-quality voice synthesis) offers a balance between performance, cost, and privacy that is often more feasible than a fully local stack.
This project exemplifies the modern “glue code” paradigm, where a developer’s skill lies in securely and efficiently integrating best-in-class services. The choice of a local LLM is the most significant security decision, effectively creating a trusted boundary. However, the attack surface shifts to the API keys for cloud services and the security of the real-time communication layer. A sophisticated attacker might target the LiveKit connection to intercept audio or attempt to poison the LLM via prompt injection through the speech-to-text service. Therefore, a defense-in-depth approach—securing each component individually and the connections between them—is non-negotiable.
Prediction:
The proliferation of AI voice agents like Riya will lead to a new wave of security challenges focused on the integrity of real-time audio data streams and the exploitation of LLM prompt structures. We will see a rise in “audio jacking” attacks designed to subtly manipulate speech-to-text transcription to inject malicious prompts into the local LLM, potentially hijacking the agent’s behavior. Furthermore, as these agents become more autonomous and are given permissions to perform actions (e.g., place real orders, control smart devices), securing the entire pipeline from microphone to action will become as critical as securing a financial transaction today. The future will demand AI-specific security frameworks that go beyond traditional API key management to include real-time anomaly detection in audio streams and robust guardrails for LLM outputs.
🎯Let’s Practice For Free:
IT/Security Reporter URL:
Reported By: Vasanthadithya Mundrathi – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅


