Listen to this Post
Introduction:
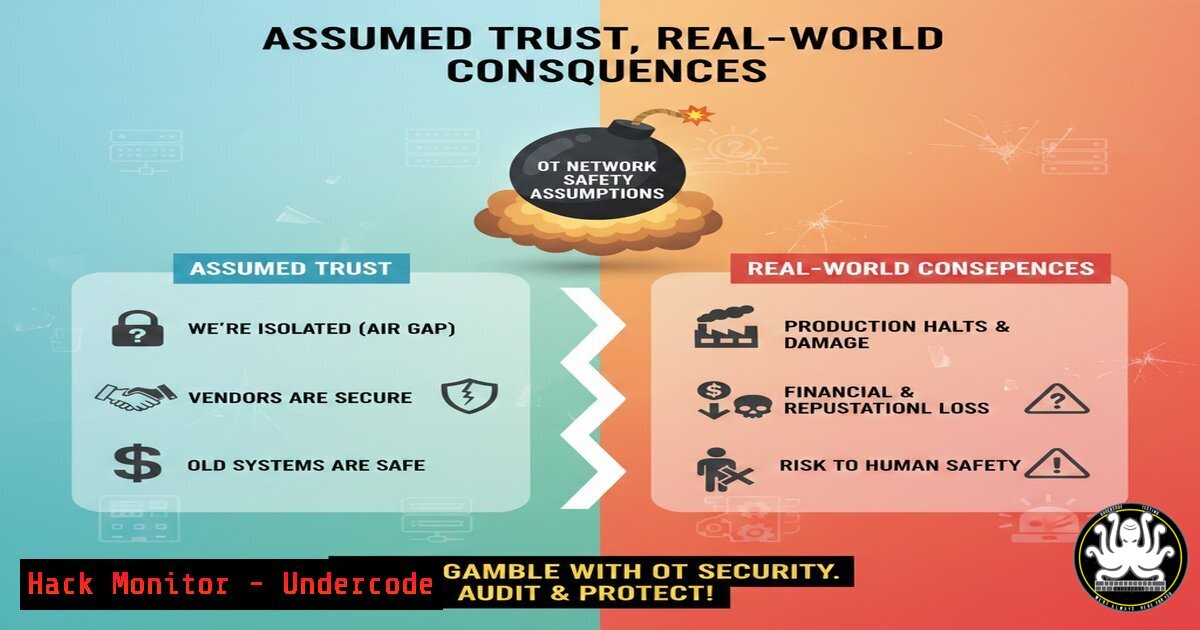
In the interconnected world of Operational Technology (OT) and Industrial Control Systems (ICS), the line between digital security and physical safety is not just blurred—it is often invisible. A recent white paper by the British Standards Institution (BSI), featuring insights from industry experts, highlights a critical and dangerous misconception: treating internal industrial networks as inherently trusted environments. This article dissects the core findings of that paper, moving beyond theory to provide a technical deep dive into the vulnerabilities created by these assumptions. We will explore how network delays, compromised communications, and misaligned security protocols can directly undermine safety instrumented systems (SIS), and provide actionable commands and configurations to audit and harden your industrial environment against these converging threats.
Learning Objectives:
- Objective 1: Analyze the risk of implicit trust in OT network segmentation and its impact on functional safety.
- Objective 2: Identify and assess vulnerabilities within Safety Instrumented Systems (SIS) that arise from network communication dependencies.
- Objective 3: Implement verification techniques and configuration audits to reconcile cybersecurity measures with safety-critical operations.
- Deconstructing the “Trusted” Internal Network: Verification and Audit
The BSI white paper’s first critical observation is that internal networks are often treated as trusted. In practice, this means once an attacker breaches the perimeter (e.g., via a phishing email or a vulnerable VPN appliance), the internal OT network offers little resistance. The implicit trust model assumes that internal traffic is safe, a dangerous fallacy in the age of sophisticated threat actors.
To move from an assumption-based security posture to a verifiable one, you must begin with network segmentation audits and traffic analysis.
Step‑by‑step guide: Auditing Network Segmentation and Trust Boundaries
- Map the Data Flow: Before running commands, understand the expected communication paths between the IT/Corporate zone, the DMZ, the Control Center (Level 3), and the actual process (Levels 0-2). Identify where your Safety Instrumented Systems (SIS) reside and which controllers they communicate with.
- Verify VLAN Segmentation (Cisco IOS Example): Log into your core switches and routers to confirm that OT devices are isolated on their own VLANs and that inter-VLAN routing is restricted.
! Check VLAN configuration show vlan brief</li> </ol> ! Verify ACLs applied to the SVI (Switch Virtual Interface) for the OT VLAN ! Example for VLAN 100 show running-config interface vlan 100 ! Look for 'access-group' statements that should restrict traffic from less trusted VLANs.
3. Analyze Live Traffic for Anomalies (Linux – tcpdump): Place a monitoring port on a span port that mirrors traffic to and from a critical PLC or Safety Controller. Capture traffic to identify any unauthorized communication.
Capture traffic on interface eth0, specifically to/from a PLC with IP 192.168.1.10 Save to a file for later analysis in Wireshark sudo tcpdump -i eth0 -w plc_traffic_analysis.pcap host 192.168.1.10 While capturing, check for protocols that shouldn't be present on the safety network segment For example, look for HTTP, FTP, or unexpected ICMP traffic. sudo tcpdump -i eth0 -n host 192.168.1.10 and not icmp and not arp
4. Test Segmentation with Ping and Traceroute: From a compromised workstation in the IT zone, attempt to reach a safety controller.
From a Windows workstation in the IT zone ping -n 3 192.168.1.10 tracert 192.168.1.10
If you get a successful reply, your segmentation is either misconfigured or non-existent. If the path stops at a firewall, that firewall is your enforcement point. The goal is to see the traffic blocked at the enforcement point.
- Safety Functions and Communication Integrity: Induced Latency and Packet Loss
The paper states that “Modern safety functions depend on reliable communications.” A safety function, such as an emergency shutdown, often relies on a sensor sending a signal to a logic solver, which then commands an actuator. If an attacker floods the network, causing delays or packet loss, this safety chain can fail, potentially leading to catastrophic physical outcomes.
Step‑by‑step guide: Simulating and Detecting Network Degradation Impact
This step involves using Linux traffic control (
tc) to simulate network degradation in a lab environment only. This should never be done on a live production system. The goal is to understand the tolerance of your safety equipment.- Set up a Test Bed: Isolate a test PLC, safety controller, and HMI. Replicate the network architecture as closely as possible.
- Introduce Latency (Simulating a congested link): On the Linux machine acting as a bridge or router between the controller and HMI, add artificial latency.
Add 200ms latency to outgoing traffic on interface eth1 sudo tc qdisc add dev eth1 root netem delay 200ms
Observe the HMI. Do alarms trigger? Does the safety logic respond slower? Does the system flag a communication fault?
- Introduce Packet Loss (Simulating a poor connection or DoS condition):
Add 5% packet loss to outgoing traffic on interface eth1 sudo tc qdisc change dev eth1 root netem loss 5%
Monitor the safety logic. Many safety protocols (like PROFIsafe) have monitoring clocks. High packet loss can cause the communication to be declared faulty, potentially forcing the system into a safe state (which might be a shutdown). Understand that an attacker could induce this to cause a spurious trip.
4. Remove the Rules:
sudo tc qdisc del dev eth1 root
3. Reconciling Security Patching with Safety Availability
A major conflict arises between the security team’s need to patch vulnerabilities and the operations team’s need for 100% uptime. The BSI paper highlights that “Well-intended security measures can introduce safety risk.” A patch might reboot a system, or a firewall rule might block a critical multicast message.
Step‑by‑step guide: Auditing Patch Conflicts and Firewall Rules
- Identify Safety-Critical Hosts: Create an inventory of all devices involved in safety functions. Note their operating systems and applications.
- Review Windows Update Policies (Windows Server/Workstation): On Windows-based HMI or engineering workstations connected to safety networks, check how updates are applied.
Check Windows Update settings via PowerShell Get-ItemProperty -Path "HKLM:\SOFTWARE\Policies\Microsoft\Windows\WindowsUpdate\AU" Check for pending reboots (a major safety risk if unplanned) Get-ItemProperty -Path "HKLM:\SYSTEM\CurrentControlSet\Control\Session Manager" -Name PendingFileRenameOperations
If `NoAutoUpdate` is set to 0 or `AUOptions` is set to auto-download and install, you have an uncoordinated patch policy that could disrupt operations.
- Audit Firewall Rules Impacting Safety Protocols: Many safety protocols use multicast or unicast on specific ports. Blocking these breaks the safety function.
– PROFINET: Uses EtherType 0x8892.
– EtherNet/IP (CIP Safety): Uses TCP/UDP 44818 for explicit messaging and UDP 2222 for implicit I/O.
– MODBUS/TCP: Uses TCP 502.On a firewall (using iptables on a Linux-based OT firewall), review rules that might be interfering.
List all iptables rules on a Linux firewall sudo iptables -L -n -v Look for rules that drop or reject traffic to/from known safety controller IPs on their specific ports. A rule like this, while well-intentioned, could be catastrophic: Chain FORWARD (policy ACCEPT) target prot opt source destination DROP tcp -- 0.0.0.0/0 192.168.1.10 tcp dpt:502
This rule drops all MODBUS/TCP traffic to the safety controller, which would be disastrous if that controller uses MODBUS for its safety-related communications.
4. Practical Hardening for Safety and Security Convergence
Moving towards a secure and safe environment requires a “Defense in Depth” strategy that explicitly acknowledges the unique requirements of safety systems. This goes beyond standard IT hardening.
Step‑by‑step guide: Implementing Secure and Safe Baselines
- Enforce the Principle of Least Privilege on Network Flows: Instead of broad VLANs, use micro-segmentation. On managed switches, implement Access Control Lists (ACLs) that permit only the specific IP-to-IP and port-to-port communications required for the process.
Example Cisco ACL on a switch port connecting to a safety PLC ! Permit only the engineering workstation to talk to the PLC on the safety protocol port access-list 101 permit tcp host 10.10.1.100 host 10.10.1.10 eq 502 ! Permit the PLC to send data to the HMI access-list 101 permit tcp host 10.10.1.10 host 10.10.2.50 eq 502 ! Deny everything else access-list 101 deny ip any any log</li> </ol> ! Apply to the interface interface GigabitEthernet0/1 ip access-group 101 in
2. Harden the Safety Controllers Themselves: Many modern safety PLCs have hardened operating systems. Ensure they are configured correctly. This is often done via the engineering software (e.g., Siemens TIA Portal, Rockwell Studio 5000).
– Disable all unused physical ports (USB, unused network ports).
– Enable and configure the controller’s built-in firewall if available.
– Set access levels with strong passwords for different modes (programming vs. run).
3. Implement Centralized Logging and Monitoring (Linux – Syslog-ng): Send all logs from firewalls, switches, and controllers (if they support syslog) to a central server for correlation and alerting.On a Ubuntu/Debian syslog-ng server sudo apt update && sudo apt install syslog-ng Edit the configuration file /etc/syslog-ng/syslog-ng.conf Add a source for network logs source s_network { syslog(ip(0.0.0.0) port(514) transport("udp")); }; Add a destination for OT logs destination d_ot_logs { file("/var/log/ot_devices/$HOST/$YEAR-$MONTH-$DAY.log"); }; Link source and destination log { source(s_network); destination(d_ot_logs); };What Undercode Say:
- Key Takeaway 1: The greatest vulnerability in OT is the assumption of safety. Implicit trust in internal networks transforms every connected device into a potential bridge between a cyber intrusion and a physical catastrophe. You cannot secure what you implicitly trust.
- Key Takeaway 2: Functional safety and cybersecurity are not separate disciplines; they are two sides of the same resilience coin. A security measure that ignores safety logic is a hazard, and a safety function that ignores network integrity is a vulnerability.
The BSI white paper underscores a fundamental shift required in industrial risk management. It is no longer sufficient for safety engineers to ignore network security, nor for IT security professionals to apply IT solutions blindly to OT environments. The analysis reveals that the convergence point is where assumptions meet reality. By actively auditing network segmentation, stress-testing communication paths in controlled settings, and meticulously reconciling security patches with operational needs, organizations can begin to dismantle the dangerous assumptions that put critical infrastructure at risk. The path forward lies in verifiable, coordinated action that treats the industrial control system as a unified, cyber-physical whole.
Prediction:
Over the next three to five years, regulatory bodies and insurance underwriters will mandate demonstrable evidence of “secure safety integration.” This will move beyond simple compliance checklists to require technical validation—including network segmentation proofs, penetration tests targeting safety instrumented functions, and documented, conflict-free patch management workflows. Organizations that fail to merge their safety and security programs will face not only escalating cyber risks but also prohibitive insurance premiums and potential regulatory shutdowns following incidents.
▶️ Related Video (80% Match):
🎯Let’s Practice For Free:
IT/Security Reporter URL:
Reported By: Durgeshkalya Tech – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅🔐JOIN OUR CYBER WORLD [ CVE News • HackMonitor • UndercodeNews ]
📢 Follow UndercodeTesting & Stay Tuned:


