Listen to this Post
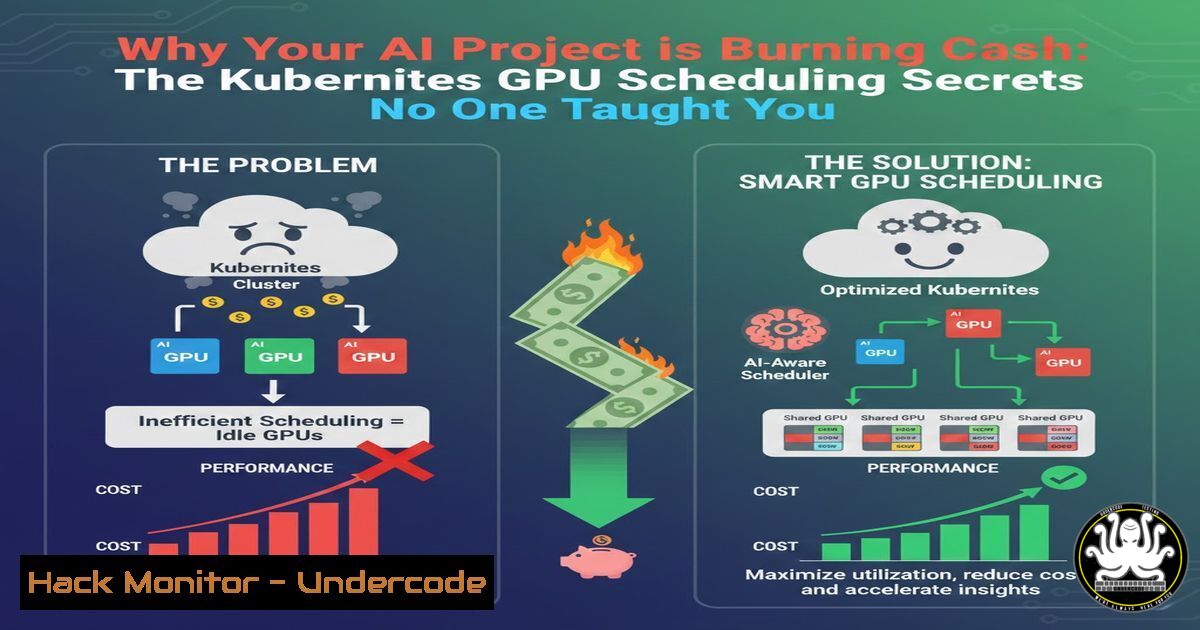
Introduction:
The explosive integration of AI workloads into production has fundamentally transformed Kubernetes from a simple container orchestrator into the critical brain of modern infrastructure. This shift is driven by the unique and costly nature of GPU resources, making efficient scheduling, security, and orchestration not just operational concerns but primary determinants of cost, performance, and security posture. Mastering Kubernetes in this context is no longer optional for engineers building reliable and economical AI systems.
Learning Objectives:
- Understand the fundamental differences between CPU and GPU scheduling in Kubernetes and their direct impact on operational costs.
- Learn to configure core Kubernetes constructs (like Taints/Tolerations and Resource Guarantees) specifically for AI training and inference workloads.
- Implement essential security hardening for AI workloads on Kubernetes, focusing on GPU access and sensitive data flows.
You Should Know:
1. GPU Scheduling: From Plumbing to Strategic Control
The core paradigm shift is that GPUs are expensive, indivisible, and scarce resources, unlike CPUs which are time-sliced. Poor scheduling leads to GPU idle time while jobs queue, directly burning cash. Kubernetes uses a combination of node labels, taints, tolerations, and resource requests to manage this.
Step-by-Step Guide:
Label GPU Nodes: First, identify and label nodes with GPUs. This allows the scheduler to target them.
kubectl label nodes <node-name> hardware-type=nvidia-gpu
Apply Taints to Reserve Nodes: Prevent non-GPU workloads from landing on these expensive nodes.
kubectl taint nodes <node-name> gpu=true:NoSchedule
Add Tolerations to GPU Workloads: In your AI job’s Pod spec, add a toleration to “accept” the taint.
apiVersion: v1 kind: Pod metadata: name: ai-training-pod spec: tolerations: - key: "gpu" operator: "Equal" value: "true" effect: "NoSchedule" containers: - name: trainer image: nvcr.io/nvidia/tensorflow:xx.xx resources: limits: nvidia.com/gpu: 2 Explicitly request GPU count
Request Resources Correctly: Use `nvidia.com/gpu` resource type in your pod’s `limits` and requests. This tells the scheduler exactly what’s needed.
- Architecting for AI Workload Patterns: Training vs. Inference
AI workloads have distinct personalities. Training jobs are long-running, batch-style, and need stability. Inference services demand low latency, high availability, and predictable scaling. Kubernetes uses different controllers and configurations for each.
Step-by-Step Guide:
For Training Jobs (Batch/Job Controller): Use the `Job` or `CronJob` API for finite tasks. Set high `restartPolicy` (OnFailure) and appropriate backoffLimit.
apiVersion: batch/v1 kind: Job metadata: name: model-train-job spec: completions: 1 parallelism: 1 template: spec: restartPolicy: OnFailure containers: - name: trainer image: training-image:latest resources: requests: nvidia.com/gpu: 4
For Inference Services (Deployment/HPA): Use `Deployments` with multiple replicas and a `HorizontalPodAutoscaler` (HPA) for demand-based scaling. Configure liveness and readiness probes.
Create an HPA targeting your inference deployment CPU/GPU usage kubectl autoscale deployment llm-inference-deploy --cpu-percent=70 --min=2 --max=10
Use PriorityClasses: Ensure critical inference pods can preempt less important batch jobs during resource crunch.
apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: inference-critical value: 1000000 globalDefault: false description: "For critical inference workloads."
3. Integrating NVIDIA NIMs for Production Model Serving
NVIDIA NIMs (NVIDIA Inference Microservices) provide optimized, containerized model servings. Kubernetes is their ideal deployment platform, enabling scaling, rolling updates, and service discovery.
Step-by-Step Guide:
Deploy as a Kubernetes Service: Package your NIM container in a Deployment and expose it via a Service for stable networking.
apiVersion: apps/v1 kind: Deployment metadata: name: llama3-nim spec: replicas: 3 selector: matchLabels: app: llama3-nim template: metadata: labels: app: llama3-nim spec: tolerations: [ ... ] containers: - name: nim image: nvcr.io/nim/llama-3:latest ports: - containerPort: 8000 apiVersion: v1 kind: Service metadata: name: llama3-nim-service spec: selector: app: llama3-nim ports: - protocol: TCP port: 80 targetPort: 8000
Implement Rolling Updates: Use the Deployment strategy to update NIM versions with zero downtime.
spec: strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1 maxSurge: 1
4. Hardening Security: The AI-Specific Threat Model
AI workloads introduce new attack surfaces: sensitive model weights in GPU memory, prompt injection via inference endpoints, and data exfiltration from training jobs. Kubernetes provides foundational controls.
Step-by-Step Guide:
Enforce Least Privilege with RBAC: Create dedicated `ServiceAccount`s for AI workloads and bind minimal roles.
Create a service account kubectl create serviceaccount ai-job-runner Create a role that only allows 'get' and 'list' on pods (example) kubectl create role pod-reader --verb=get,list --resource=pods Bind the role to the service account kubectl create rolebinding ai-read-pods --role=pod-reader --serviceaccount=default:ai-job-runner
Isolate Workloads with Namespaces: Separate teams (e.g., research, prod-inference) using namespaces as a boundary for network policies and quotas.
kubectl create namespace ai-prod-inference kubectl create namespace ai-research
Apply Network Policies: Restrict pod-to-pod communication. For example, only allow ingress to inference pods from the ingress controller.
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-ingress-to-inference namespace: ai-prod-inference spec: podSelector: matchLabels: app: llm-inference policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: name: ingress-namespace
5. Cost Governance and Resource Optimization
Unchecked AI workloads can lead to exponential cloud bills. Kubernetes native tools provide visibility and enforcement.
Step-by-Step Guide:
Set Resource Quotas per Namespace: Prevent a single team from consuming all cluster GPUs.
apiVersion: v1 kind: ResourceQuota metadata: name: gpu-quota namespace: ai-research spec: hard: requests.nvidia.com/gpu: "4" limits.nvidia.com/gpu: "4"
Implement LimitRanges: Define default GPU/CPU requests and limits for Pods in a namespace, preventing over-provisioning.
Monitor with Metrics Server & Prometheus: Track actual GPU utilization (DCGM exporter) versus request to identify underutilized resources and right-size requests.
What Undercode Say:
- Kubernetes is the New AI Operating System. Its role has evolved from container management to being the central nervous system that arbitrates access to the most critical and expensive compute resources (GPUs), directly governing the performance, cost, and reliability of AI systems.
- Security is Inherent, Not Bolted-On. For AI workloads processing sensitive data and IP, the Kubernetes control plane (RBAC, Network Policies, Namespaces) forms a critical part of the trust boundary. Configuring it correctly is as important as securing the models themselves.
The analysis reveals a maturation in the AI stack. As models become commodities, the competitive advantage shifts to the efficiency and robustness of the operational platform. Kubernetes expertise, specifically tailored to the nuances of GPU workloads and AI lifecycle stages (training, fine-tuning, inference), is now a high-value specialization. The post correctly identifies that the financial stakes of poor orchestration are too high to ignore, making deep Kubernetes literacy a non-negotiable for engineering teams shipping AI in production.
Prediction:
By 2026, we will see the rise of “AI-Aware Schedulers” as a standard Kubernetes extension or as a dedicated layer atop it. These schedulers will use predictive analytics based on model type, job history, and cluster telemetry to make near-optimal GPU placement and scaling decisions autonomously. Furthermore, security frameworks will emerge that provide seamless encryption for GPU memory and attestation for AI workload integrity, with Kubernetes APIs serving as the primary control surface. Failure to adopt these advanced orchestration and security practices will result in organizations facing unsustainable operational costs and becoming prime targets for AI-specific data exfiltration attacks.
▶️ Related Video (76% Match):
🎯Let’s Practice For Free:
IT/Security Reporter URL:
Reported By: Michael Harris – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅


