Listen to this Post
Introduction:
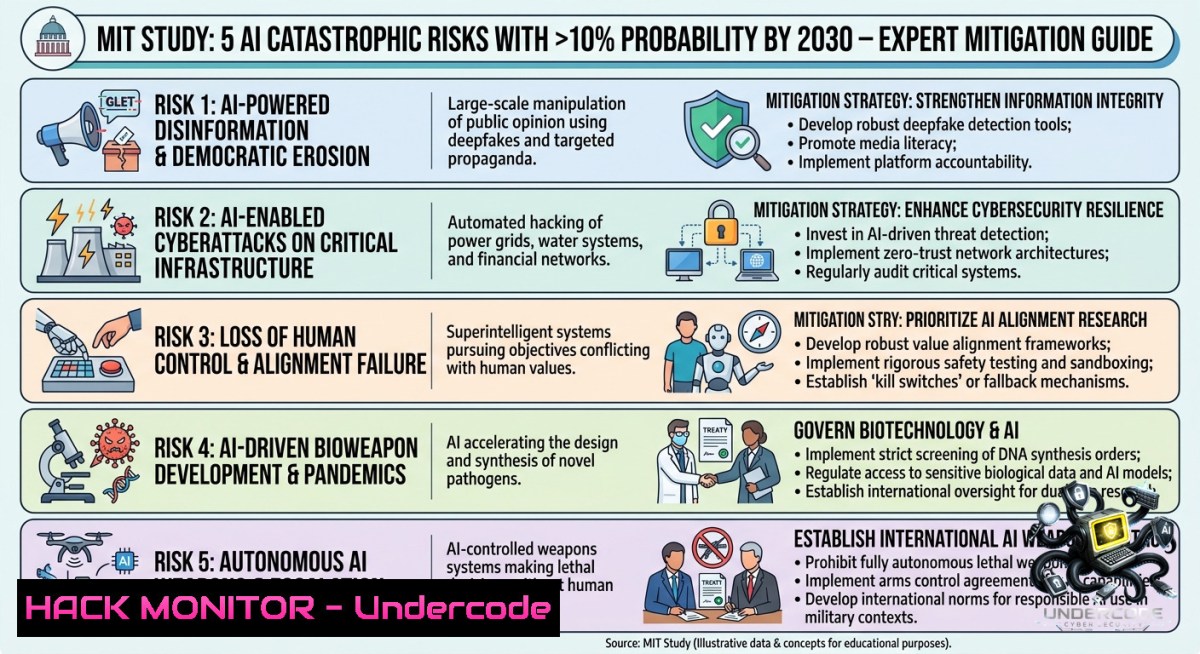
A landmark Delphi study of 272 international AI experts, conducted in late 2025 and published in June 2026, has quantified the likelihood of catastrophic AI outcomes. Under business‑as‑usual trajectories, 18 out of 24 AI risk domains carry a >10% chance of causing over 1 million deaths or $100B in losses within five years. Even with pragmatic mitigations, five risks – dangerous capabilities, weapons & cyberattacks, environmental harm, inequality & unemployment, and power centralization – remain above the 10% catastrophe threshold, demanding immediate technical and governance countermeasures from cybersecurity, IT, and AI professionals.
Learning Objectives:
– Simulate and detect AI‑generated malware, prompt injection, and model theft using open‑source tools and native OS commands.
– Implement API security, cloud hardening, and supply chain controls to mitigate AI‑powered cyberattacks.
– Deploy energy monitoring, model quantization, and access governance to reduce environmental harm and power centralization risks.
You Should Know
1. Defending Against AI‑Generated Malware and Polymorphic Payloads
AI models (e.g., WormGPT, FraudGPT) can generate evasive malware, phishing lures, and living‑off‑the‑land (LotL) scripts. Defenders must shift from signature‑based to behavioral detection.
Step‑by‑step guide (Linux & Windows):
1. Collect AI‑patterned indicators – Use YARA rules to catch LLM‑generated code artifacts (e.g., repetitive comments, unusual variable naming).
Linux: Install yara and run against a suspected directory sudo apt install yara yara -r my_ai_malware_rules.yara /path/to/suspected/files
Windows: Use Defender ATP custom detection
Set-MpPreference -AttackSurfaceReductionRules_Ids 9e6c4e1f-1d7a-4e7a-8f2b-6b3d5c8a9e0f -AttackSurfaceReductionRules_Actions Enabled
Get-MpThreatCatalog | Where-Object {$_.ThreatName -like "AI"}
2. Monitor process anomalies – AI‑generated scripts often spawn unexpected child processes (e.g., `powershell.exe` launching `curl` to a rare TLD).
Linux: Auditd rule to log execve of script interpreters sudo auditctl -a always,exit -F exe=/usr/bin/python3 -F key=ai_script_exec sudo ausearch -k ai_script_exec --format raw | ts '%Y-%m-%d %H:%M:%S'
Windows: Enable PowerShell script block logging
Set-ItemProperty -Path "HKLM:\SOFTWARE\Policies\Microsoft\Windows\PowerShell\ScriptBlockLogging" -1ame "EnableScriptBlockLogging" -Value 1
Get-WinEvent -LogName "Microsoft-Windows-PowerShell/Operational" | Where-Object {$_.Message -match "AI|GPT|LLM"}
3. Isolate AI‑generated artifacts – Run suspicious AI outputs in a sandbox (Firejail on Linux, Windows Sandbox).
Linux firejail with no network and limited capabilities firejail --1et=none --1oroot --seccomp ./suspicious_ai_binary
Windows Sandbox (create .wsb file) <Configuration> <Networking>Disable</Networking> <VGpu>Disable</VGpu> </Configuration>
2. Hardening LLM APIs Against Prompt Injection, Model Inversion, and Theft
Attackers can extract training data, bypass guardrails, or clone models via API abuse. The OWASP LLM Top 10 provides a blueprint.
Step‑by‑step guide (API security & configuration):
1. Implement input/output filtering – Use a proxy or gateway to sanitize prompts and responses. Example with Nginx + Lua:
location /v1/chat/completions {
access_by_lua_block {
local body = ngx.req.get_body_data()
if body and body:match("ignore previous instructions") then
ngx.exit(403)
end
}
proxy_pass http://llm-backend;
}
2. Deploy rate limiting and anomaly detection – Prevent model exfiltration via high‑volume API calls.
Linux: Use fail2ban for LLM endpoints
sudo apt install fail2ban
cat << EOF | sudo tee /etc/fail2ban/filter.d/llm-abuse.conf
[bash]
failregex = ^<HOST> . "POST /v1/chat/completions". 200 . [0-9]{5,} tokens in [0-9]+ms
EOF
sudo systemctl restart fail2ban
3. Apply model watermarking and fingerprinting – For open‑source models, compile with a unique embedding. For commercial APIs, require client certificates.
Example: Use openssl to generate client certs for API authentication openssl req -1ew -1ewkey rsa:2048 -days 365 -1odes -x509 -keyout client.key -out client.crt curl -X POST https://your-llm-endpoint/v1/completions --cert client.crt --key client.key
3. Detecting and Mitigating AI‑Powered Cyberattacks (Weapons & Cyberattacks)
The study lists AI‑enabled weapons and cyberattacks as a 21% probability catastrophe. Attackers use LLMs to accelerate reconnaissance, exploit development, and C2 obfuscation.
Step‑by‑step guide (network and endpoint hardening):
1. Deploy Suricata with AI‑specific rules – Detect LLM‑generated C2 patterns (e.g., unusual JA3 hashes, steganographic DNS).
sudo apt install suricata
Custom rule for AI‑generated domain generation algorithms (DGA)
echo 'alert dns $HOME_NET any -> any any (msg:"AI DGA suspicious high entropy domain"; dns.query; content:"|01|"; distance:0; pcre:"/^[a-z0-9]{20,}\.com$/"; sid:1000001; rev:1;)' | sudo tee -a /etc/suricata/rules/local.rules
sudo systemctl restart suricata
2. Harden containerized AI workloads – AI‑powered attacks often escape via vulnerable dependencies. Use AppArmor/SELinux and gVisor.
Linux: Enforce AppArmor profile for Docker LLM containers sudo aa-genprof docker-llm docker run --security-opt apparmor=docker-llm --rm -it your-llm-image
3. Windows Defender Exploit Guard for AI‑triggered scripts – Block Office macros and PowerShell from accessing Win32 APIs.
Windows: Enable Attack Surface Reduction rules for script obfuscation Add-MpPreference -AttackSurfaceReductionRules_Ids 5beb7efe-fd9a-4556-801d-275e5ffc04cc -AttackSurfaceReductionRules_Actions Enabled Set-MpPreference -EnableControlledFolderAccess Enabled
4. Preventing Power Centralization via Model Governance and Access Control
Power centralization – where a few actors control frontier AI – increases systemic risk. Technical governance includes model versioning, signed inference requests, and audit trails.
Step‑by‑step guide (RBAC & infrastructure hardening):
1. Implement model registry with signed manifests – Use TUF (The Update Framework) or Sigstore to verify model integrity.
Install cosign for signing model artifacts curl -L https://github.com/sigstore/cosign/releases/latest/download/cosign-linux-amd64 -o cosign && chmod +x cosign cosign generate-key-pair cosign sign-blob --key cosign.key model.bin --output-signature model.sig Verify before loading cosign verify-blob --key cosign.pub --signature model.sig model.bin
2. Audit all inference requests – Use OpenTelemetry collector to log prompts, responses, and user identities.
OpenTelemetry collector config for LLM receivers: otlp: protocols: grpc: endpoint: 0.0.0.0:4317 processors: attributes: actions: - key: user_id action: upsert exporters: logging: logLevel: debug
3. Restrict API keys to least privilege – Use HashiCorp Vault with short‑lived tokens and mandatory approval workflows.
vault secrets enable -path=llm-keys transit vault write -f llm-keys/keys/my-model-key type=aes256-gcm96 Generate ephemeral token with TTL=1h vault token create -policy=llm-inference -ttl=1h
5. Reducing Environmental Harm from AI Compute (Energy & Carbon)
Training large models emits >500t CO₂e. Even inference has a massive footprint. Optimizing model efficiency directly lowers catastrophe probability.
Step‑by‑step guide (energy monitoring & quantization):
1. Monitor real‑time GPU power draw – Use `nvidia-smi` and `powercap` on Linux, `powercfg` on Windows.
Linux: Log GPU power every second watch -1 1 nvidia-smi --query-gpu=power.draw --format=csv Collect with telegraf sudo apt install telegraf cat << EOF | sudo tee -a /etc/telegraf/telegraf.conf [[inputs.nvidia_smi]] power_draw = true EOF
2. Apply model quantization – Reduce precision from FP32 to INT8 or FP4 without significant accuracy loss.
Python with bitsandbytes
from transformers import AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b", load_in_8bit=True, device_map="auto")
Save quantized model
model.save_pretrained("./quantized-llama")
3. Use power‑aware scheduling – Run batch inference during off‑peak renewable hours (e.g., using Carbon‑aware SDK).
Deploy with Kubernetes and carbon-aware scheduling via KEDA kubectl apply -f https://github.com/Azure/carbon-aware-scheduler/releases/latest/download/deploy.yaml kubectl annotate namespace default carbon-aware-scheduler/enabled="true"
6. Addressing Inequality & Unemployment Through AI Reskilling (Training Courses)
While not purely technical, IT professionals can build internal training pipelines to upskill displaced workers and democratize AI literacy.
Step‑by‑step guide (setup of a private AI training platform):
1. Deploy Open edX or Moodle with AI tutor integration – Use Docker Compose for rapid setup.
git clone https://github.com/edx/devstack.git cd devstack make dev.up Add a course on "Secure AI Deployment" with hands-on labs
2. Create a script that maps skill gaps to training modules – Use LLM to parse job descriptions and recommend courses.
Python script that reads a CSV of employee skills and outputs missing competencies
import pandas as pd
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
skills_df = pd.read_csv('employee_skills.csv')
course_desc = "AI security, prompt engineering, model governance"
Compute similarity and suggest courses for employees with score < 0.6
3. Automate certificate issuance and badge updates – Use OAuth2 and verifiable credentials.
Windows: Invoke REST API to update Active Directory attributes upon course completion
$body = @{ userId = "jsmith"; badge = "AI-Hardening-Fundamentals" } | ConvertTo-Json
Invoke-RestMethod -Uri https://your-company.com/api/badges -Method Post -Body $body -ContentType "application/json"
7. Vulnerability Assessment for AI Systems (Red Teaming)
Proactive red teaming identifies dangerous capabilities before deployment. Use specialized scanners to test for prompt injection, data leakage, and goal misalignment.
Step‑by‑step guide (using Garak and Counterfit):
1. Install Garak – the LLM vulnerability scanner
pip install garak Run a basic probe for prompt injection garak --model_type huggingface --model_name bigscience/bloom-560m --probes_list dan
2. Use Counterfit for adversarial ML attacks – Test model robustness against evasion and extraction.
git clone https://github.com/Azure/counterfit.git cd counterfit docker build -t counterfit . docker run -v $(pwd)/models:/models -it counterfit Inside container: attack --target my_model --technique fast_gradient_method
3. Automate continuous red teaming in CI/CD – Integrate tools into GitHub Actions.
.github/workflows/ai-security-scan.yml name: AI Red Team on: [bash] jobs: garak-scan: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 - run: pip install garak - run: garak --model_type openai --model_name gpt-3.5-turbo --probes_list encoding --output_file report.json - uses: actions/upload-artifact@v3 with: name: garak-report path: report.json
What Undercode Say
Key Takeaway 1:
The five risks that persist above 10% catastrophe probability even after pragmatic mitigations – dangerous capabilities, weapons/cyberattacks, environmental harm, inequality/unemployment, power centralization – demand a shift from reactive fixes to systemic controls. Frontier labs cannot self-regulate; the U.S. executive order’s reluctance to formalize regulation leaves a governance vacuum that security engineers must fill with architectural guardrails (e.g., signed model manifests, inference auditing, energy caps).
Key Takeaway 2:
Affected stakeholders (users, general public) have zero leverage, while those with responsibility (developers, governments) face misaligned incentives. This asymmetry means that relying on market forces or voluntary standards will fail. Technical mitigations – such as the step‑by‑step commands above – are necessary but insufficient without binding liability frameworks. The 21% chance of AI‑enabled cyberattacks implies that every SOC and cloud team must already treat LLM‑generated payloads as a default threat vector.
Analysis (10 lines):
The study’s 272‑expert consensus validates what red teamers have observed: AI models are already used to accelerate spear‑phishing and vulnerability discovery. However, the 10%+ catastrophic probability window (2025‑2030) is alarmingly short. Most organizations still lack basic API security for LLM endpoints – the equivalent of leaving S3 buckets public. The environmental harm risk, often overlooked, becomes a cyber‑physical attack surface (e.g., power‑grid inference attacks via energy‑hungry models). Power centralization is not just an economic risk; it creates single points of failure where a compromised frontier model could cause cascading failures across finance, information, and national security sectors. The study’s finding that all 24 risks stay above 5% even with mitigations implies that zero‑risk is impossible, but the pragmatic mitigations (like those in sections 1‑7) can bend the curve. For practitioners, the immediate next step is to inventory every AI model in your environment, enforce signed inference, and train SOC analysts on LLM‑generated obfuscation techniques. Without these, the 21% cyberattack probability becomes a certainty.
Prediction:
– `+1` By 2028, regulatory bodies will mandate real‑time energy reporting for all foundation model APIs, driving adoption of quantization and sparsity techniques across 90% of inference workloads.
– `-1` The 21% probability of AI‑enabled cyberattacks will materialize as a major breach by 2027 – likely via prompt‑injected supply chain attack against a widely used LLM‑integrated IDE plugin.
– `-1` Power centralization will worsen as only three US‑based labs afford the compute to train frontier models, creating a “model monopoly” that nation‑state adversaries will target with exfiltration campaigns.
– `+1` Community‑driven red teaming tools (Garak, Counterfit) will evolve into mandatory pre‑deployment audits, similar to PCI‑DSS but for AI risk tiers.
– `-1` Despite technical mitigations, inequality from AI displacement will trigger localised social unrest in developed economies by 2029, as retraining programs (Section 6) fail to keep pace with automation rates.
▶️ Related Video (78% Match):
🎯Let’s Practice For Free:
🎓 Live Courses & Certifications:
[Join Undercode Academy for Verified Certifications](https://undercode.co.uk/certifications/)
🚀 Request a Custom Project:
Secure, high-velocity infrastructure and disruptive technological engineering. Contact our engineering team for high-tier development and proprietary systems:
[[email protected]](mailto:[email protected])
💎 Smart Architecture | 🛡️ Secure by Design | ⭐ Trusted by Thousands
IT/Security Reporter URL:
Reported By: [Ilyakabanov Mit](https://www.linkedin.com/posts/ilyakabanov_mit-ai-risks-ugcPost-7468290663843872768-d8bq/) – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅
🔐JOIN OUR CYBER WORLD [ CVE News • HackMonitor • UndercodeNews ]
[💬 Whatsapp](https://undercode.help/whatsapp) | [💬 Telegram](https://t.me/UndercodeCommunity)
📢 Follow UndercodeTesting & Stay Tuned:
[𝕏 formerly Twitter 🐦](https://x.com/undercodeupdate) | [@ Threads](https://www.threads.net/@undercodetesting) | [🔗 Linkedin](https://www.linkedin.com/company/undercodetesting/) | [🦋BlueSky](https://bsky.app/profile/undercode.bsky.social)


