Listen to this Post
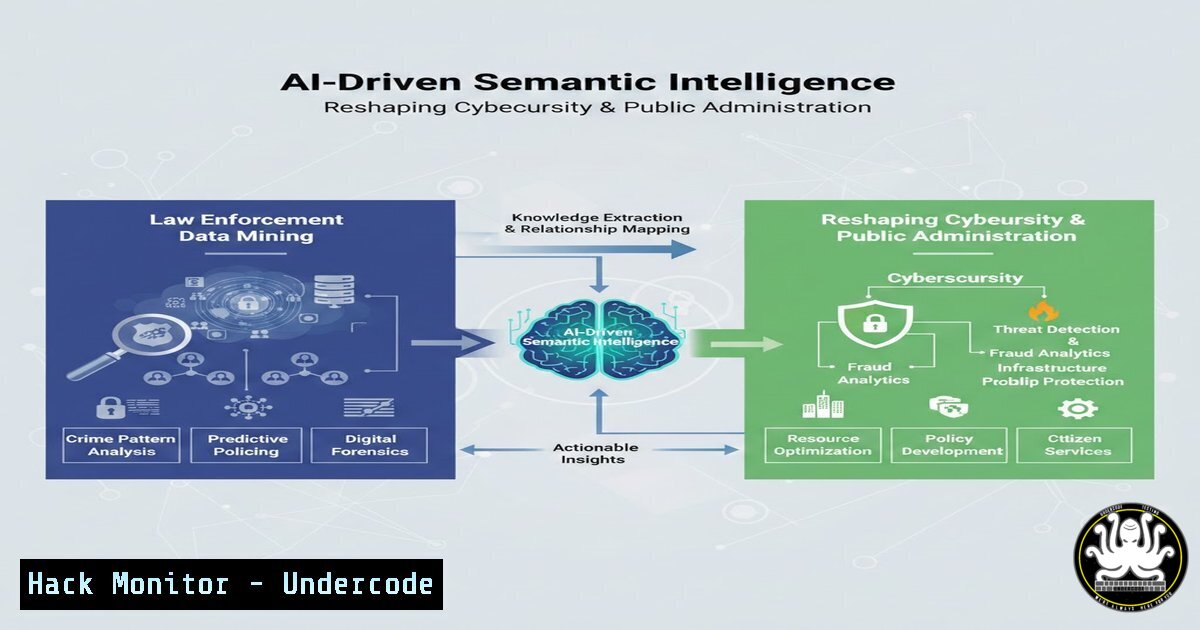
Introduction:
The convergence of Artificial Intelligence (AI) and Semantic Web technologies is creating a paradigm shift in how we handle unstructured data, particularly within high-stakes environments like law enforcement and public administration. By moving beyond simple keyword searches to understanding the context and relationships within data, these systems enable the automated extraction and organization of critical information from narrative reports. This not only enhances interoperability between agencies but also provides a powerful new vector for cyber threat intelligence, allowing security professionals to mine reports for Indicators of Compromise (IoCs) and attack patterns that would otherwise remain buried in plain text.
Learning Objectives:
- Understand the core concepts of Semantic Web technologies (RDF, OWL, SPARQL) and their role in structuring unstructured data.
- Learn how AI-driven data mining can be applied to extract actionable cybersecurity intelligence from law enforcement and incident reports.
- Explore practical command-line and coding techniques to simulate the extraction and querying of semantic data.
You Should Know:
- Deconstructing the Research: AI and Semantic Systems in Public Administration
The highlighted research, “Interoperable Semantic Systems in Public Administration: AI-Driven Data Mining from Law Enforcement Reports,” focuses on solving a fundamental problem: data silos and unstructured information. Law enforcement reports are typically narrative texts, rich with entities (people, places, objects), events, and relationships. For a human analyst, cross-referencing thousands of these reports is a monumental task. This is where AI and Semantic Web technologies step in.
– The AI Component: Natural Language Processing (NLP) and machine learning models are used to perform Named Entity Recognition (NER) and relationship extraction. The AI scans the text and identifies key elements, such as a specific malware variant, a command-and-control server IP address, a suspect’s alias, or a modus operandi.
– The Semantic Component: Once extracted, this information isn’t just stored in a database; it is transformed into a knowledge graph using standards like the Resource Description Framework (RDF) and the Web Ontology Language (OWL). This creates a web of interconnected data where the relationships are explicit (e.g., “Suspect A used Malware X to target Sector Y”).
To understand the “extraction” part, we can simulate a simple version of this process on Linux using command-line tools.
Example: Simulating Entity Extraction from a report.txt file.
Simulate a law enforcement report snippet
cat > report.txt << EOF
On October 26th, the threat actor tracked as "GreyNoise" utilized a phishing campaign
targeting the financial sector. The emails contained a malicious attachment,
"invoice-74612.pdf", which attempted to download a payload from the IP address
185.130.5.133. The malware sample, identified as "Emotet" variant 42, established
persistence via the Windows Registry.
EOF
Use grep and regex to simulate extraction of IP addresses and file names
echo " Extracted IP Addresses "
grep -oE '\b([0-9]{1,3}.){3}[0-9]{1,3}\b' report.txt
echo -e "\n Extracted File Names "
grep -oE '\b[a-zA-Z0-9._-]+.pdf\b' report.txt
echo -e "\n Extracted Malware Names "
grep -oE '\b(Emotet|TrickBot|Ryuk)\b' report.txt
- Building the Knowledge Graph: From Extracted Data to RDF Triples
After extracting entities, the next step is to structure them. In the semantic web, data is stored as “triples”: Subject-Predicate-Object. For example, “Malware_Emotet” – “hasVariant” – “42”. We can use Python to generate these triples, which can then be loaded into a triplestore like Apache Jena or GraphDB.
Example: Python script to generate RDF triples in Turtle format.
generate_triples.py
entities = [
("incident:1", "dc:date", '"2024-10-26"'),
("incident:1", "ns:hasThreatActor", "ta:GreyNoise"),
("ta:GreyNoise", "rdf:type", "ns:ThreatActor"),
("incident:1", "ns:hasMalware", "mal:Emotet"),
("mal:Emotet", "ns:variant", '"42"'),
("mal:Emotet", "ns:hasC2", "ip:185.130.5.133"),
]
print("@prefix ns: <a href="http://example.org/ns">http://example.org/ns</a> .")
print("@prefix ta: <a href="http://example.org/actors">http://example.org/actors</a> .")
print("@prefix mal: <a href="http://example.org/malware">http://example.org/malware</a> .")
print("@prefix ip: <a href="http://example.org/ip">http://example.org/ip</a> .")
print("@prefix dc: <a href="http://purl.org/dc/elements/1.1/">http://purl.org/dc/elements/1.1/</a> .")
print("@prefix rdf: <a href="http://www.w3.org/1999/02/22-rdf-syntax-ns">http://www.w3.org/1999/02/22-rdf-syntax-ns</a> .\n")
for s, p, o in entities:
print(f"{s} {p} {o} .")
Running the script: `python3 generate_triples.py > output.ttl`
This output can now be queried, allowing an analyst to ask complex questions like “Find all IP addresses linked to the Emotet malware.”
- Querying the Semantic Web: The Power of SPARQL
With data stored in a knowledge graph, analysts can use SPARQL (SPARQL Protocol and RDF Query Language) to perform complex, relationship-based queries that are impossible with traditional SQL. For a security operations center (SOC), this means being able to correlate seemingly unrelated data points from years of reports in milliseconds.
Example: A SPARQL query to find all command-and-control servers used by a specific threat actor.
PREFIX ns: <a href="http://example.org/ns">http://example.org/ns</a>
PREFIX mal: <a href="http://example.org/malware">http://example.org/malware</a>
SELECT ?c2_ip ?malware_name
WHERE {
?incident ns:hasThreatActor ta:GreyNoise .
?incident ns:hasMalware ?malware .
?malware ns:hasC2 ?c2_ip .
?malware ns:variant ?malware_name .
}
This query traverses the graph: from the incident, to the actor, to the malware, and finally to the C2 IP address, revealing the infrastructure used in an attack.
4. Automating Intelligence Gathering with Python and APIs
In a real-world scenario, this process is automated. We can use Python to fetch reports from an API, run them through an NLP model, and push the resulting triples to a knowledge graph. This creates a self-updating intelligence database. Here’s a conceptual snippet using the `requests` and a hypothetical NLP library:
import requests
from hypothetical_nlp_lib import extract_entities
<ol>
<li>Fetch a report from a public source (e.g., a security blog's API)
response = requests.get("https://api.threatintel.com/reports/latest")
report_text = response.json()['content']</li>
</ol>
report_text = "New analysis on LockBit 3.0 shows it now uses IP 192.168.1.100 for exfiltration."
<ol>
<li>Extract entities (simplified for demonstration)
entities = extract_entities(report_text)
Simulated output:
entities = {
'malware': 'LockBit 3.0',
'ip': '192.168.1.100'
}</p></li>
<li><p>Convert to RDF triple and POST to a triplestore
triple = f"ns:Incident_{hash(report_text)} ns:hasMalware mal:{entities['malware'].replace(' ', '_')} ."
requests.post("http://localhost:3030/ds/update", data=triple)</p></li>
</ol>
<p>print(f"Triple generated: {triple}")
print("Data ingested into knowledge graph.")
- Securing the Semantic Infrastructure: Cloud Hardening and API Security
Implementing such a system requires a secure architecture. The triplestore (e.g., Apache Jena Fuseki) is often hosted in the cloud. Hardening this is critical.
– Authentication: Always enable authentication on the SPARQL endpoints. Use strong passwords or integrate with OAuth2/OIDC.
– Network Segmentation: Place the triplestore in a private subnet. The application layer (the Python script) should be the only component with direct access.
– Input Validation: If you have a public-facing API to submit reports, it must be hardened against injection attacks. Malicious SPARQL queries (SPARQL injection) could be used to extract or delete data.
Example: Nginx configuration to reverse-proxy and secure a Fuseki instance.
server {
listen 443 ssl;
server_name graph.undercode.local;
ssl_certificate /etc/nginx/ssl/undercode.crt;
ssl_certificate_key /etc/nginx/ssl/undercode.key;
location / {
Fuseki typically runs on port 3030
proxy_pass http://127.0.0.1:3030/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
Basic Authentication
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/.htpasswd;
}
}
What Undercode Say:
- Key Takeaway 1: The future of threat intelligence lies in knowledge graphs. By transforming unstructured incident reports into a semantic knowledge graph, organizations can move from reactive, signature-based detection to proactive, context-aware hunting. An analyst can instantly see the entire attack chain—actor, tools, infrastructure, and target—for any given indicator.
- Key Takeaway 2: This research is a blueprint for cross-domain interoperability. The same technology that connects law enforcement reports can connect SOCs, IT departments, and cloud security teams. A phishing email reported to one agency can automatically enrich the threat intelligence feeds of every connected organization, drastically reducing the time to detection and response.
The analysis presented in the MDPI paper is not just an academic exercise; it is a direct application of cutting-edge AI to solve a critical operational challenge. By automating the synthesis of information, we empower defenders with a level of situational awareness previously unattainable. The combination of NLP for extraction and semantic web technologies for connection creates a force multiplier for cybersecurity, turning mountains of raw data into a single, coherent, and queryable defense network.
Prediction:
Within the next three to five years, we will see the emergence of national and international “Threat Intelligence Knowledge Graphs” as a standard component of Critical National Infrastructure (CNI) protection. This will move cyber defense from a collection of disparate, private threat feeds to a collaborative, semantic web of shared knowledge. The primary challenge will shift from data collection to data governance, access control, and ensuring the integrity of the information within the graph to prevent poisoning attacks by adversaries.
▶️ Related Video (80% Match):
🎯Let’s Practice For Free:
IT/Security Reporter URL:
Reported By: Alexandros Spyropoulos – Hackers Feeds
Extra Hub: Undercode MoN
Basic Verification: Pass ✅


